Integration Services and Software Solutions
Validate strategic direction with on-the ground technical problem-solvers and no vendor lock-in
Accelerate capacity constrained engineering teams

A mech suit for generative AI. 🕹️
- Prompt GPTs with live data
- Convert API/Webpage data to vector embeddings
- Synthesize datasets from natural language
Dispatch prompts as a part of a crul query pipeline. Use expansion to asynchronously run the same or a tokenized prompt across a data set. Include live API/Webpage data in your prompts and chain prompts together.
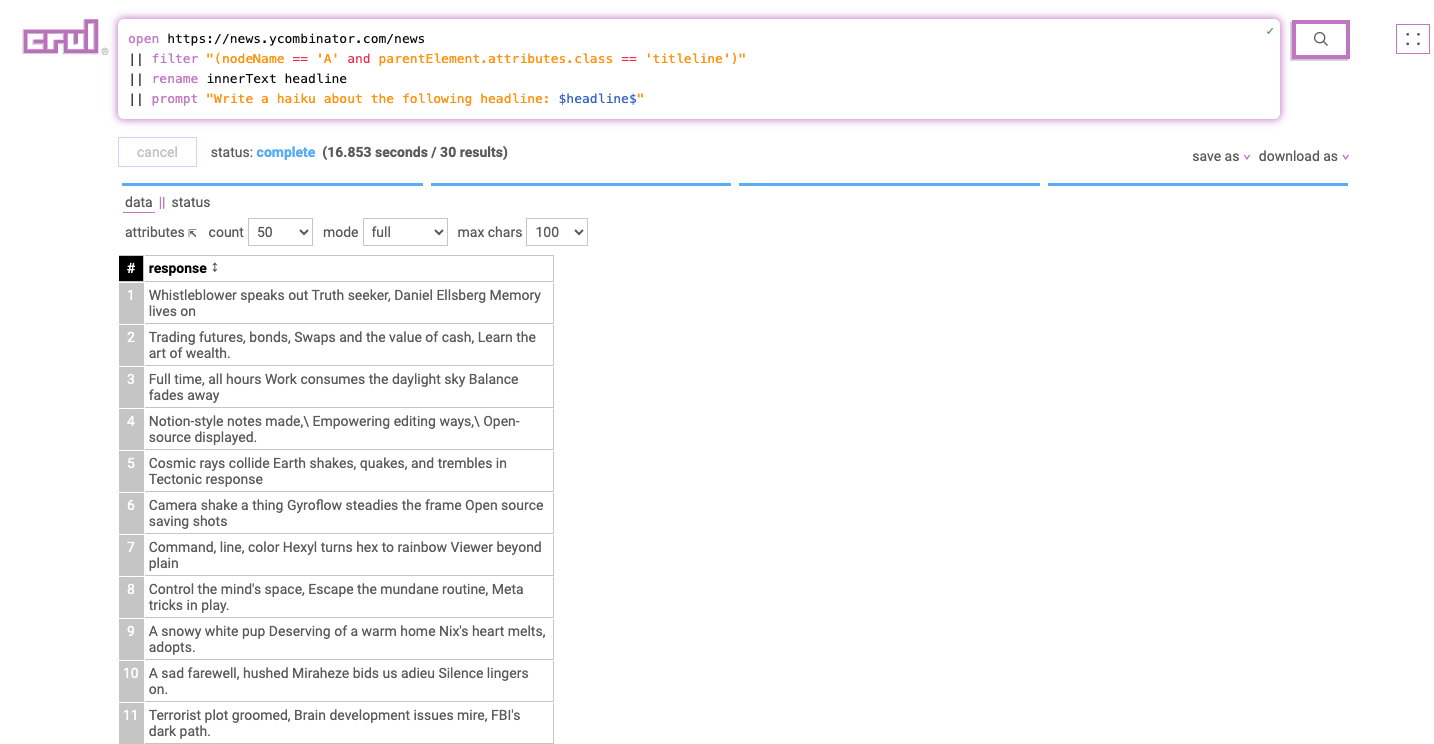
open https://news.ycombinator.com/news
|| filter "(nodeName == 'A' and parentElement.attributes.class == 'titleline')"
|| rename innerText headline
|| prompt "Write a haiku about the following headline: $headline$"
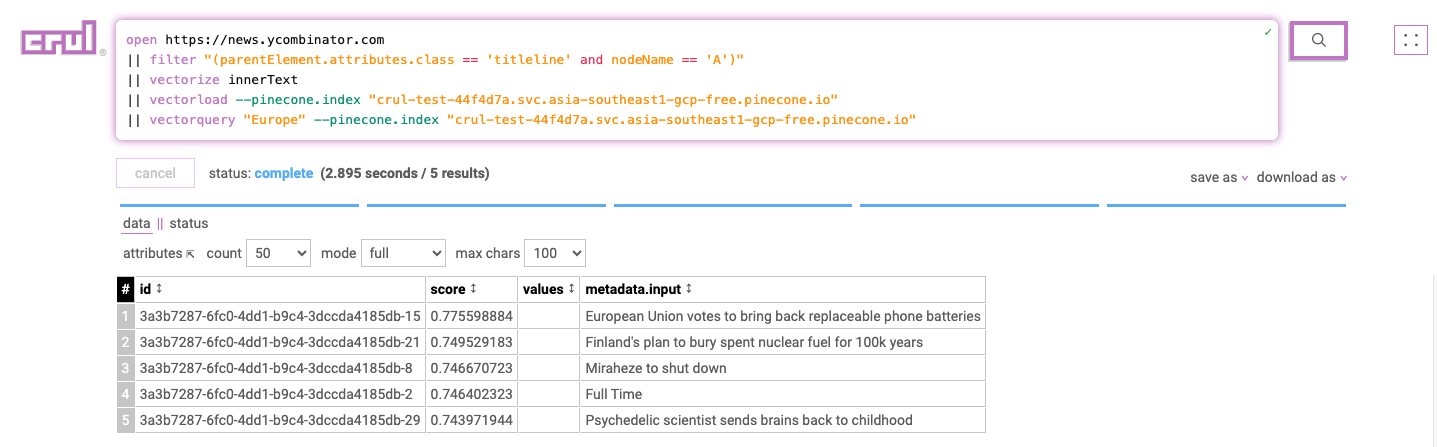
Generate vector emebeddings from data and push to a vector database. Use the vectorquery command to semantically query the database.
open https://news.ycombinator.com
|| filter "(parentElement.attributes.class == 'titleline' and nodeName == 'A')"
|| vectorize innerText
|| vectorload --pinecone.index "crul-test-44f4d7a.svc.asia-southeast1-gcp-free.pinecone.io"
|| vectorquery "relating to Europe" --pinecone.index "crul-test-44f4d7a.svc.asia-southeast1-gcp-free.pinecone.io"
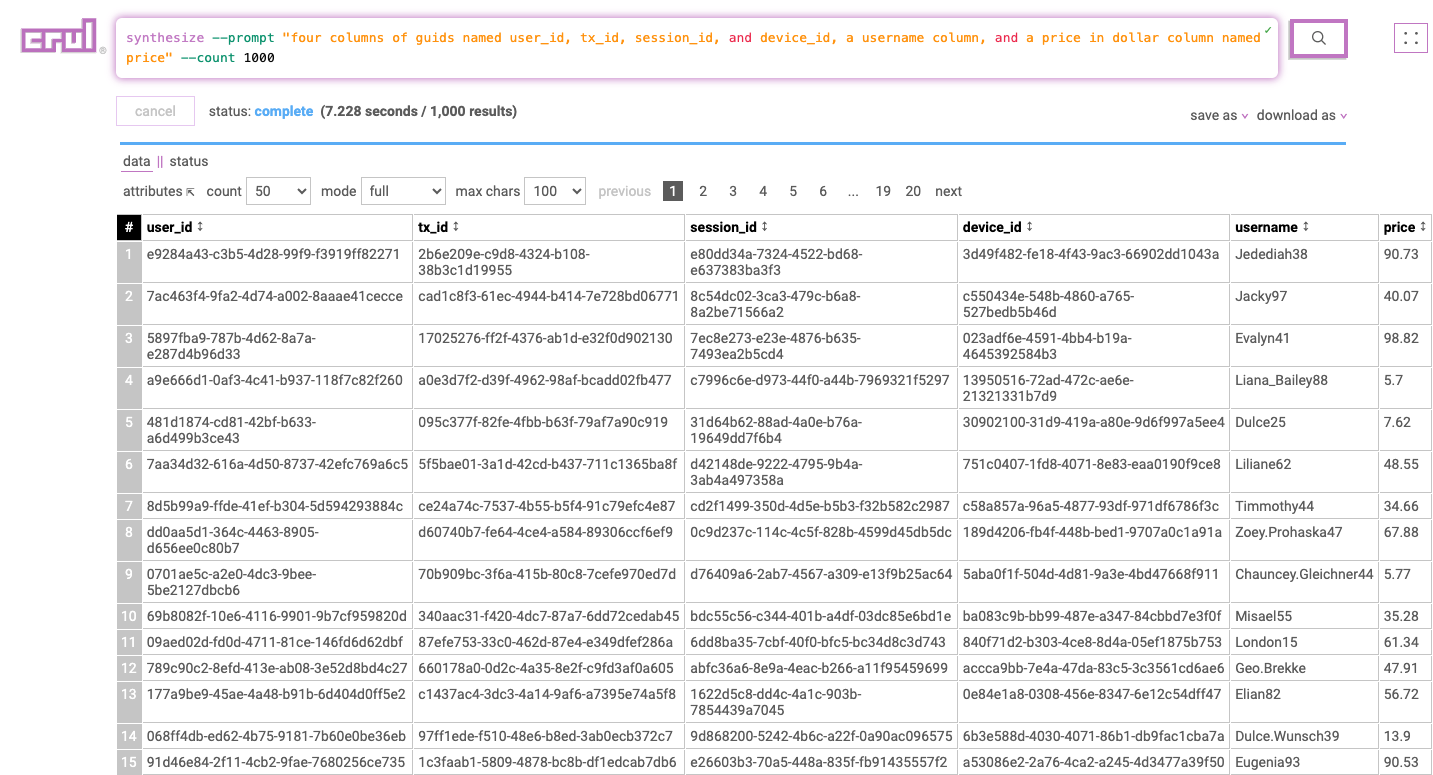
Generate synthetic data sets using natural language prompts, as well as sampled from real data.
synthesize
--prompt "add a random product (named product) which is either a tablet, a phone, or a computer, add a random price (named price), add a timestamp (named ts), a guid (named tx_id)"
--count 100
Lights, camera,  'n IT! ✨
'n IT! ✨
- Latest Hacker News Comments (Web)
- Latest Hacker News Comments (API)
- Shopify Product Prices (Web)
- Latest Tweets (API)
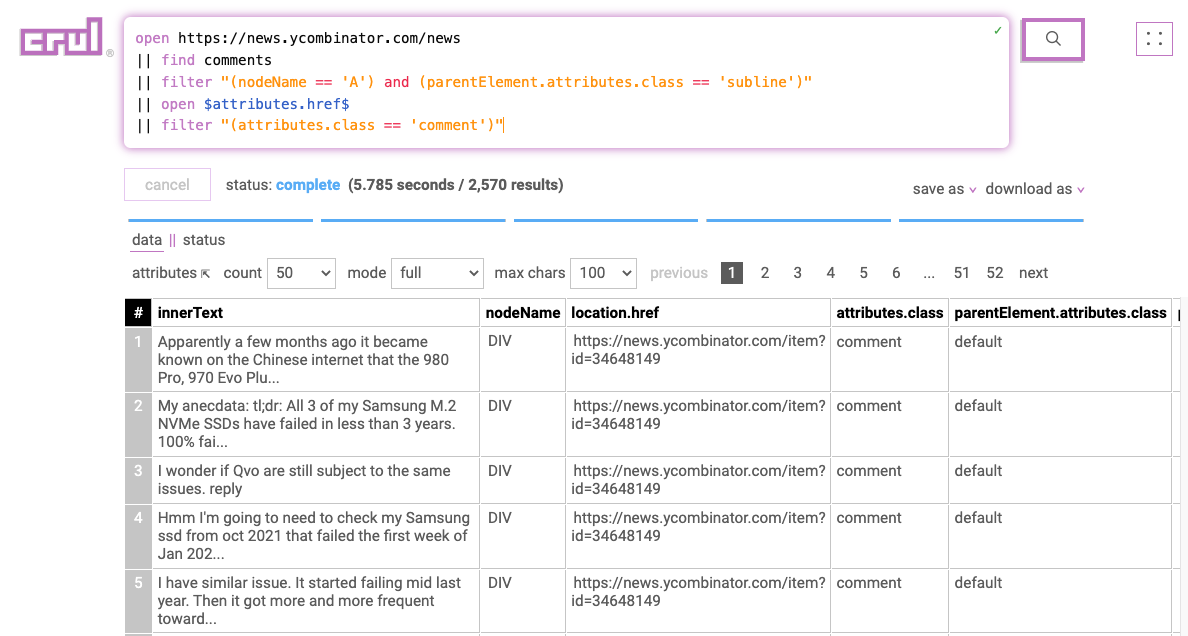
open https://news.ycombinator.com/news
|| find comments
|| filter "(nodeName == 'A') and (parentElement.attributes.class == 'subline')"
|| open $attributes.href$
|| filter "(attributes.class == 'comment')"
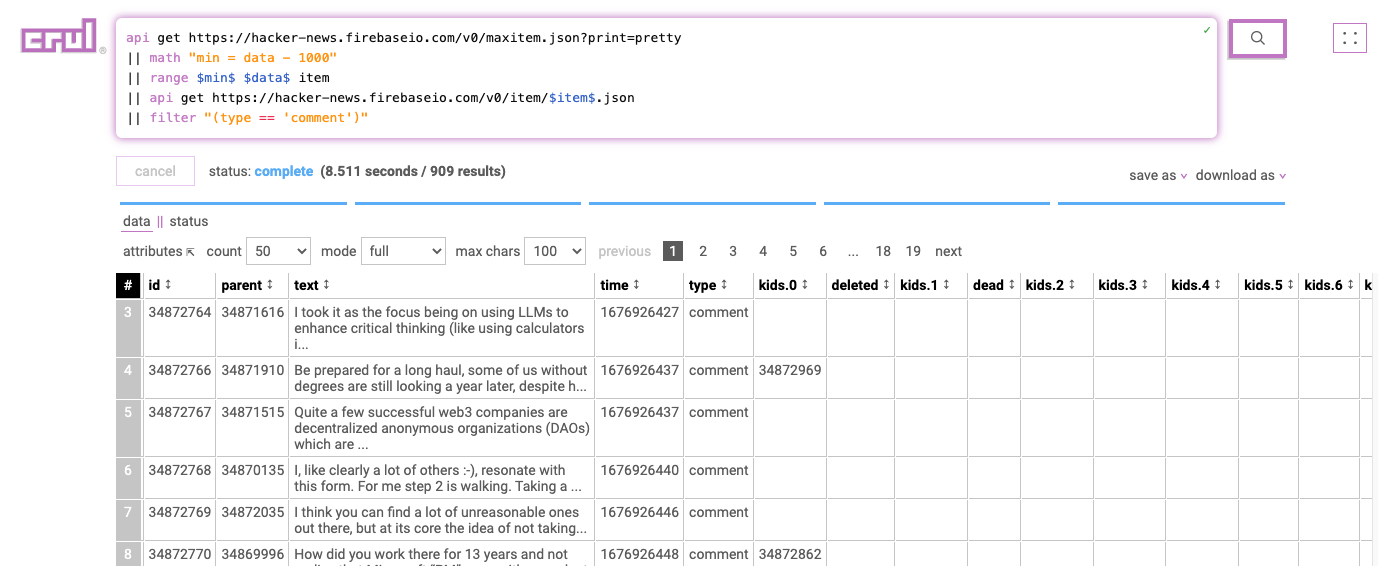
api get https://hacker-news.firebaseio.com/v0/maxitem.json?print=pretty
|| math "min = data - 10"
|| range $min$ $data$ item
|| api get https://hacker-news.firebaseio.com/v0/item/$item$.json
|| filter "(type == 'comment')"
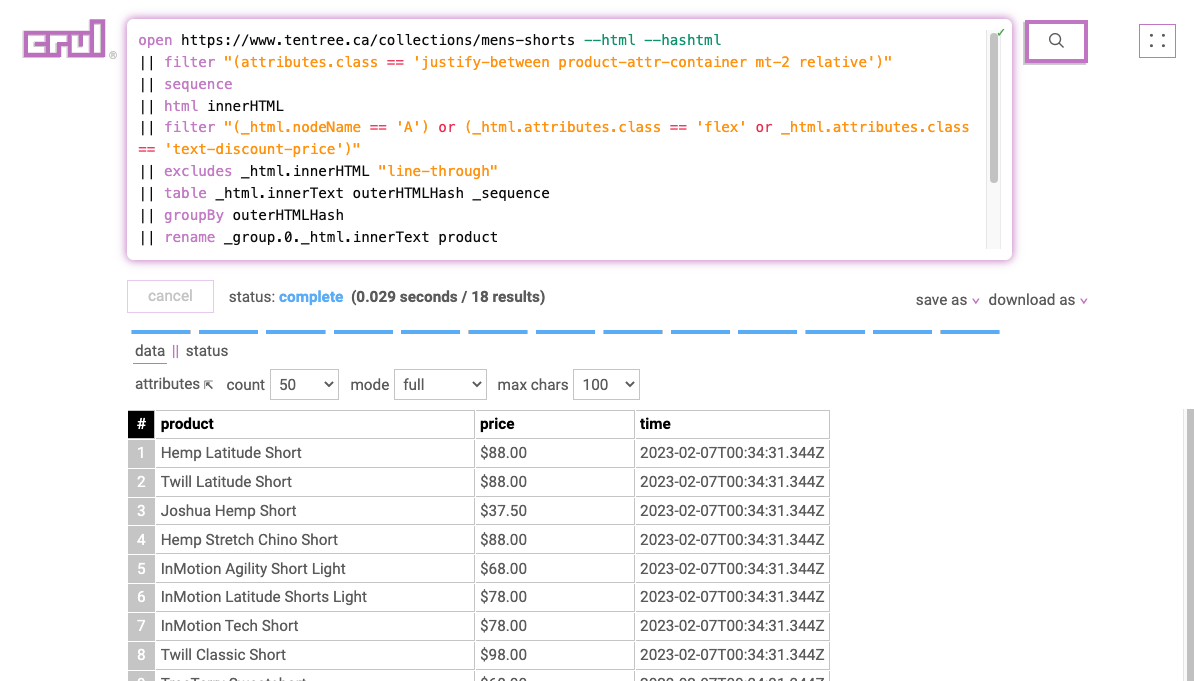
open https://www.tentree.ca/collections/mens-shorts --html --hashtml
|| filter "(attributes.class == 'justify-between product-attr-container mt-2 relative')"
|| sequence
|| html innerHTML
|| filter "(_html.nodeName == 'H3') or (_html.attributes.class == 'flex' or _html.attributes.class == 'text-discount-price')"
|| excludes _html.innerHTML "line-through"
|| table _html.innerText outerHTMLHash _sequence
|| groupBy outerHTMLHash
|| rename _group.0._html.innerText product
|| rename _group.1._html.innerText price
|| sort _group.0._sequence --order "ascending"
|| addcolumn time $TIMESTAMP.ISO$
|| table product price time
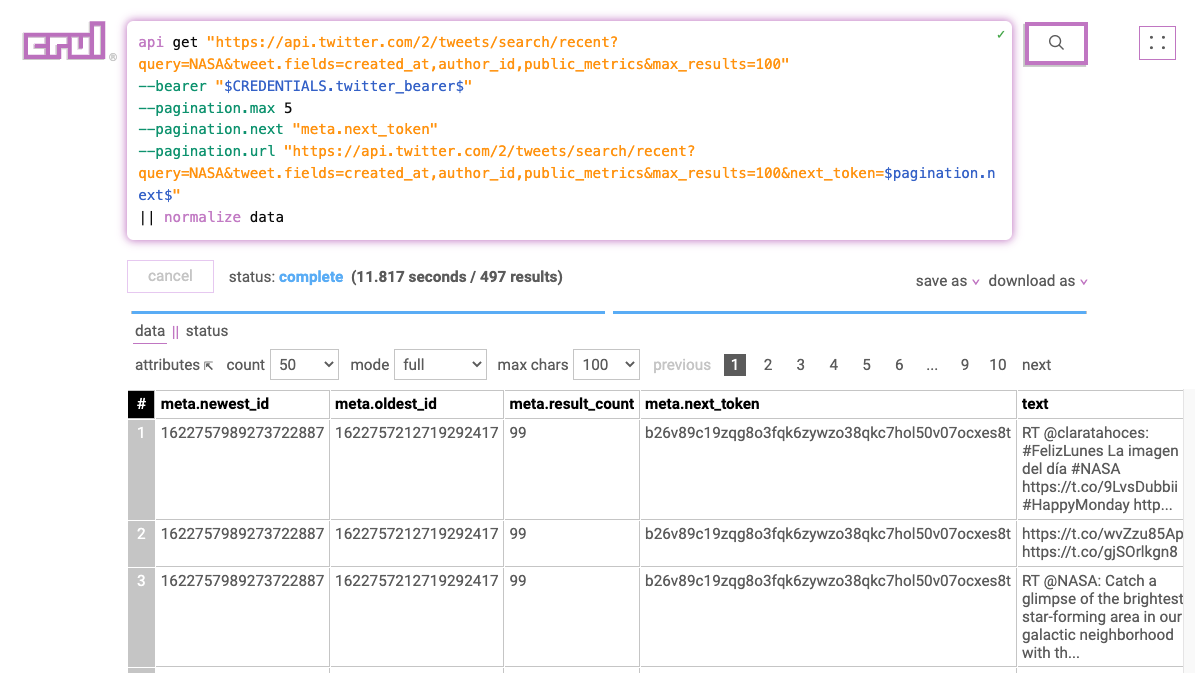
api get "https://api.twitter.com/2/tweets/search/recent?query=NASA&tweet.fields=created_at,author_id,public_metrics&max_results=100"
--bearer "$CREDENTIALS.twitter_bearer$"
--pagination.max 5
--pagination.next "meta.next_token"
--pagination.url "https://api.twitter.com/2/tweets/search/recent?query=NASA&tweet.fields=created_at,author_id,public_metrics&max_results=100&next_token=$pagination.next$"
|| normalize data
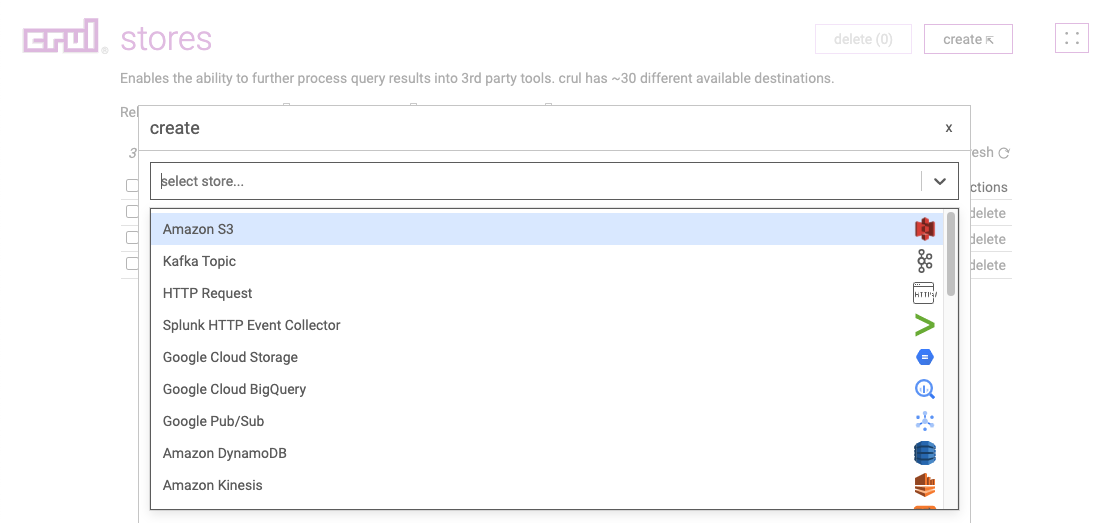
Dreamy Webpage and API data feeds. 🌜
- Export Crul Results to Kafka/etc.
- Scheduled Export of Crul Results to Kafka/etc.
- Download Crul Results to CSV/JSON
- Retrieve Crul Results By API
...
|| freeze --store "kafka-prod" --kafka.topic "hn_comments"
Configure queries to run on a set interval and export to the destination of your choice. Use the diff command to maintain rolling diffs of only new content, or push entire results set on each run.
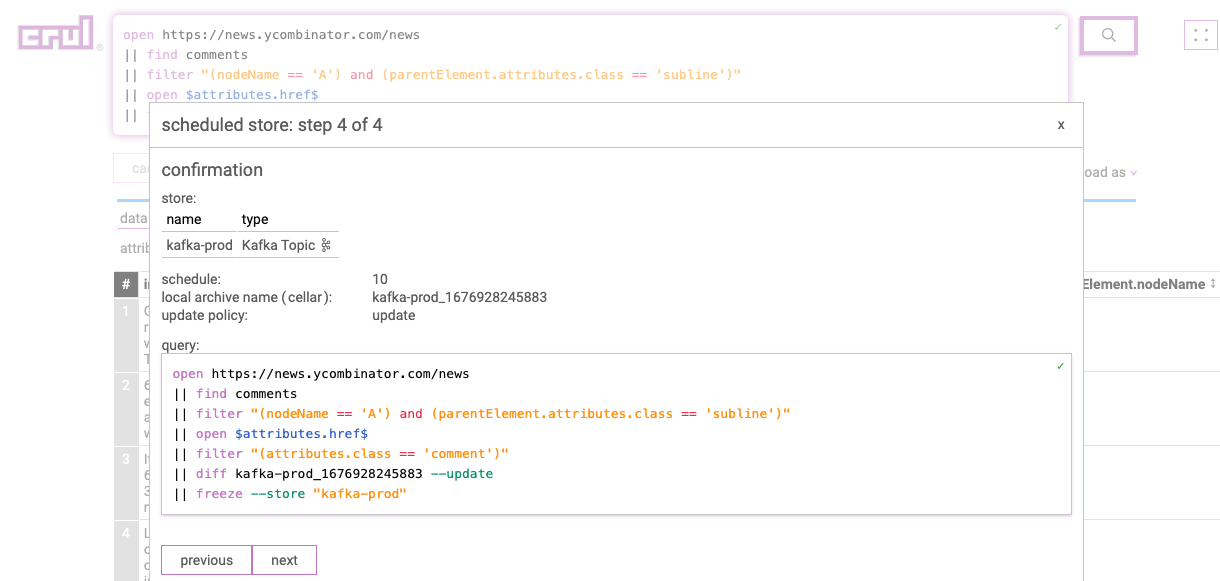
Download results to a local CSV or JSON file and further process in the data analysis tool of your choice.
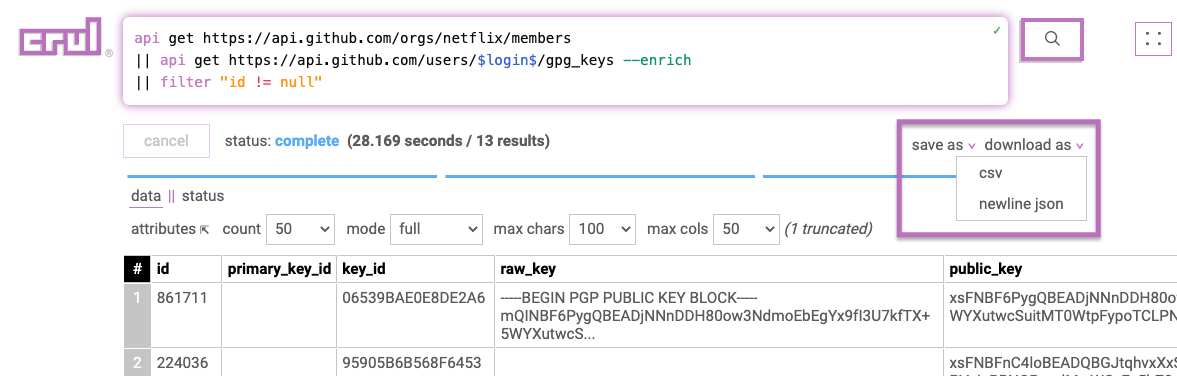
Use the crul API to dispatch queries and read results.
curl -X 'POST' 'http://localhost:1968/v1/sirp/query/runner/dispatch' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H "Authorization: crul {token}" \
-d '{ "query": "devices" }'
Yeah, can do a whole lot... 🎨
Push incremental changes
Compare results from previous results and only retain what is new.
Learn more ↗Client authentication for OAuth
Authenticate with multiple OAuth providers in order to access protected API data.
Learn more ↗Vectorize data
Generate vector embeddings from data, upload to vector databases, and semantically query.
Learn more ↗Domain throttling
Control the interval of accessing a domain based on custom prescribed rate limit policies.
Learn more ↗Run queries with your favorite language
Access the query results with auth keys and the REST API.
Learn more ↗