Prompts
The prompt command is a powerful way to dispatch prompts as a part of a crul query pipeline. The combination of crul's core api and open commands with the prompt command allow you to include real time, live web and/or API data in your prompts, which can bypass some of the limitations of existing models trained on historic data.
How it works
The prompt command uses OpenAI's API. Over time more models will be supported. You can integrate with other models that expose an API using the api command. See the OpenAI template for an example.
Note: The prompt command requires auth, so you'll first need to configure an openai credential containing your OpenAI API key with the name openai.
Single prompt
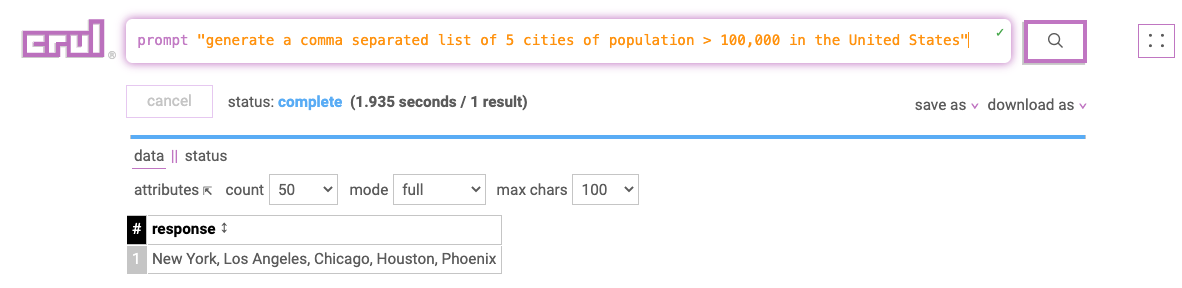
Query
prompt "generate a comma separated list of 5 cities of population > 100,000 in the United States"
Results
Chained prompts
Using the || syntax, we can chain multiple prompts together. When used in combination with tokenization and expanding stages, you can asynchrnously dispatch multiple prompts at once based on the results of a previous stage.
Another nice feature of crul when working with prompts is the stage and command level caching, which allows you to only focus on the last stage/prompt of your query, you do not need to rerun the entire chain. This can be overriden at the stage level using the global --cache false flag.
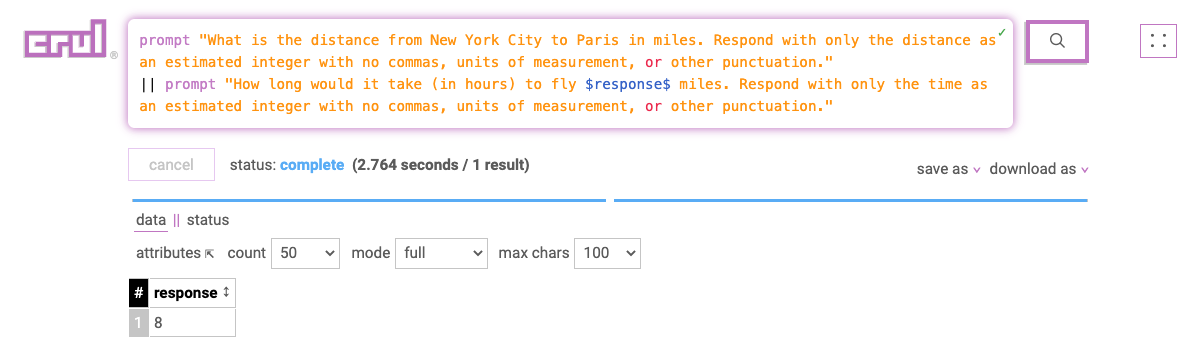
Query
prompt "What is the distance from New York City to Paris in miles. Respond with only the distance as an estimated integer with no commas, units of measurement, or other punctuation."
|| prompt "How long would it take (in hours) to fly $response$ miles. Respond with only the time as an estimated integer with no commas, units of measurement, or other punctuation."
Results
Combination with api/open
We can take the output of query using the api/open commands, and use the prompt command to create prompts based on live web or API data.
For example, let's get all the headlines from the Hacker News homepage, then ask OpenAI to create a haiku based on each headline. Notice the $headline$ token in the prompt which allows us to create dynamic, previous stage dependent prompts.
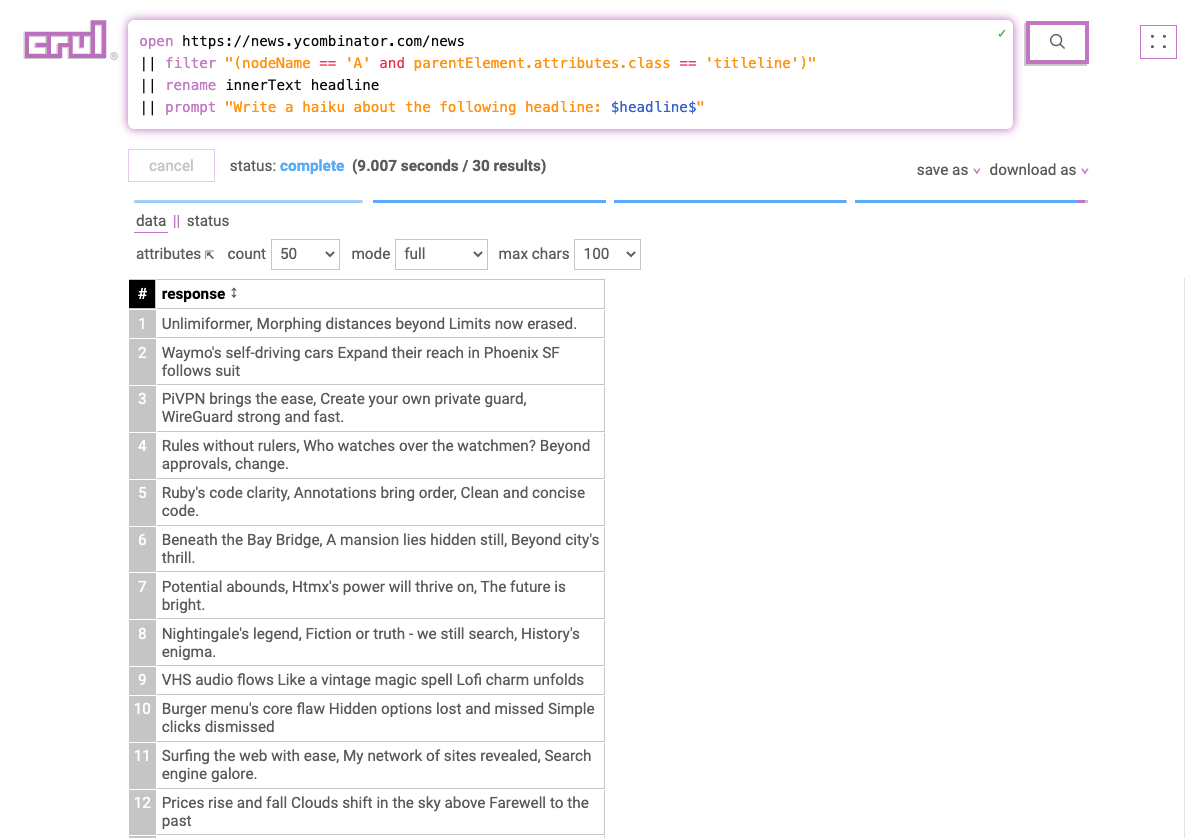
Query
open https://news.ycombinator.com/news
|| filter "(nodeName == 'A' and parentElement.attributes.class == 'titleline')"
|| rename innerText headline
|| prompt "Write a haiku about the following headline: $headline$"
Results
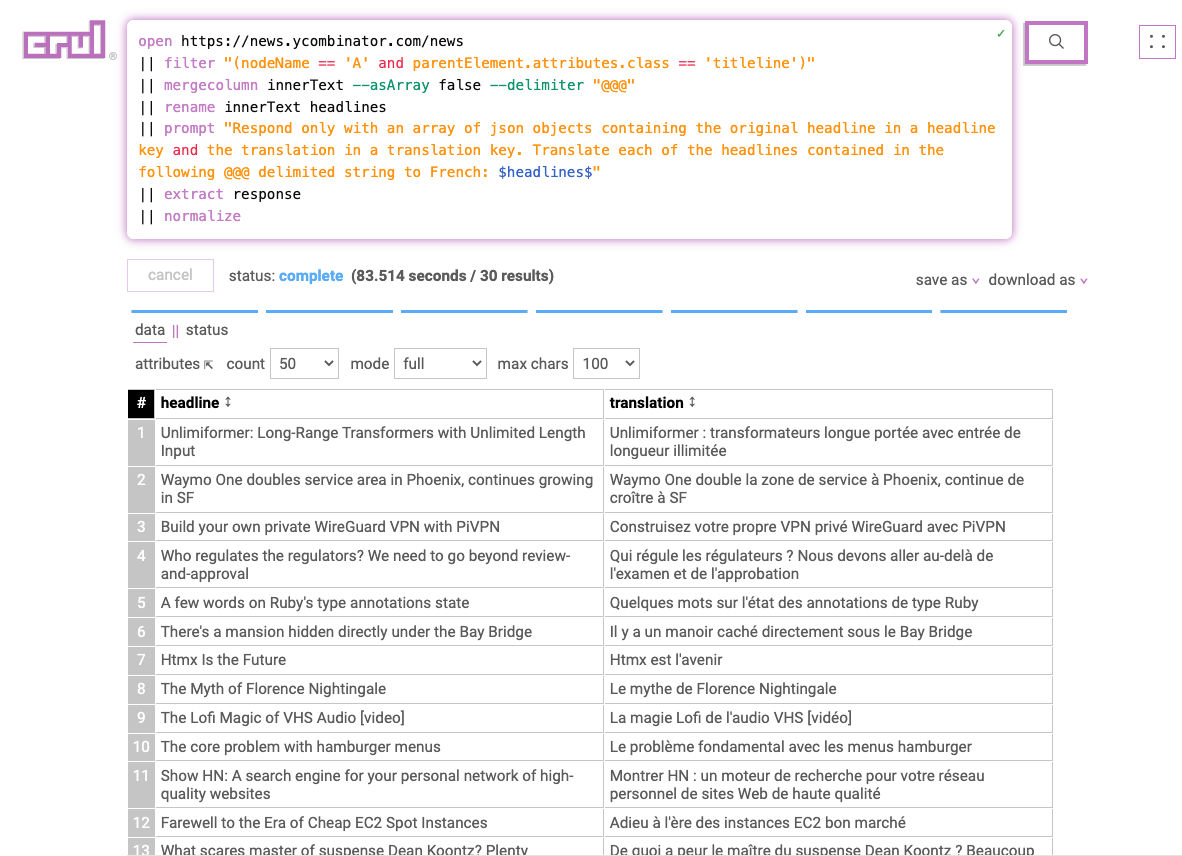
Combination with other comands
What's different about the next query is that we'll use the filter commands and the mergecolumn command to merge the headlines into a single row containing a @@@ delimited string to pass into a single request. This isn't neccessary, however it reduces the number of requests we make. We'll also use the rename command to make our prompt a little more clear.
The last two stages (extract and normalize) of the query will extract the JSON response and expand it into rows.
For similar queries, you will need to write your prompt accordingly to let the model understand the data structure you are providing it with.
Query
open https://news.ycombinator.com/news
|| filter "(nodeName == 'A' and parentElement.attributes.class == 'titleline')"
|| mergecolumn innerText --asArray false --delimiter "@@@"
|| rename innerText headlines
|| prompt "Respond only with an array of json objects containing the original headline in a headline key and the translation in a translation key. Translate each of the headlines contained in the following @@@ delimited string to French: $headlines$"
|| extract response
|| normalize
Results