
Intro
Many of you have probably already tried using OpenAI's API to interact with available AI models. crul's natural API interaction and expansion principles make it easy to create generative AI workflows that dynamically generate and chain together prompts.
Although this blog is limited to OpenAI's API and ChatGPT related models, you can use the same concepts to chain together or distribute prompts across multiple models.
First contact
Let's start small and run a single prompt.
Note: The OpenAI API requires auth, so you'll first need to configure a basic credential containing your OpenAI API key with the name openai.
Running a single prompt
This query uses the prompt command to run a simple prompt using OpenAI's API.
prompt "Write a haiku about APIs"
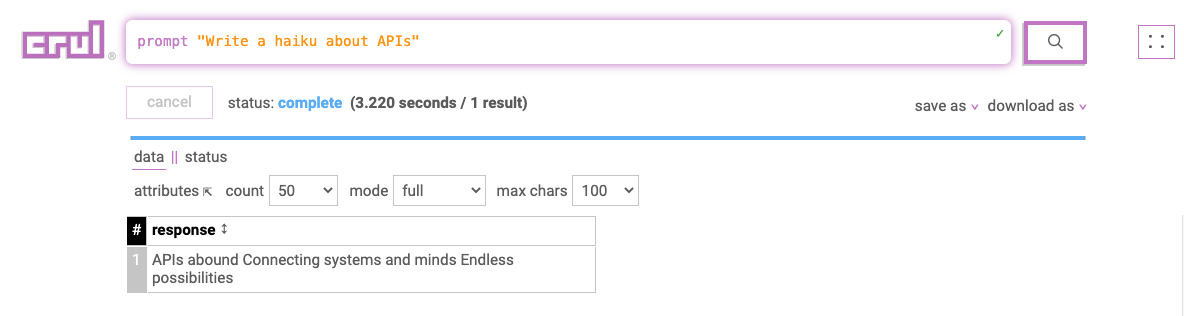
Note: If you rerun this query, you'll get back the cached results. You can bypass the cache using the --cache false global flag.
Another way to run this query is with a template from crul's query library. You can think of this template as a macro for the expanded query described in the Template explanation at the end of this post. This template will show you the underlying implementation of the prompt command using the api command.
Chaining prompts
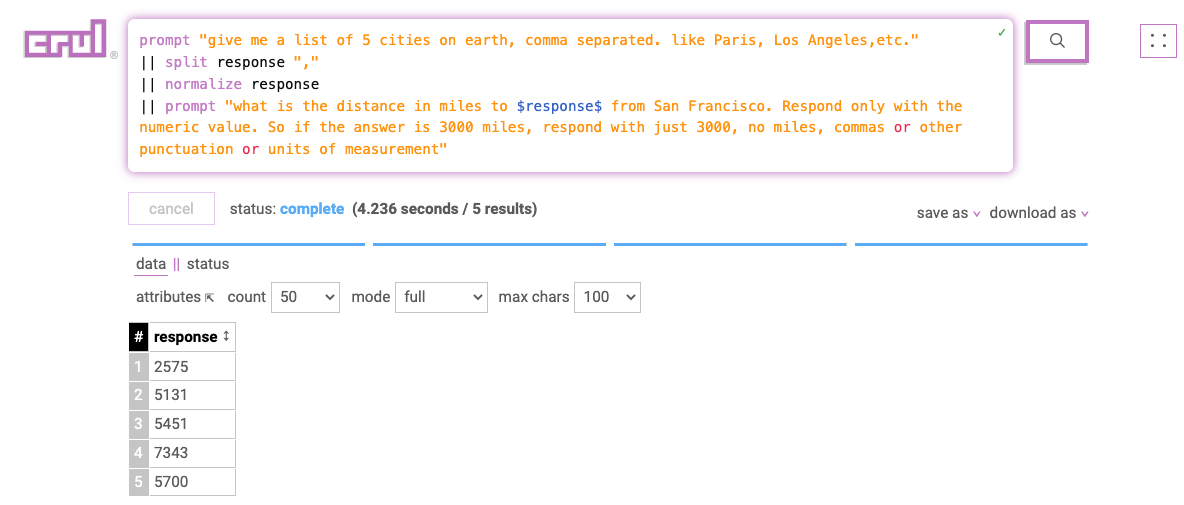
One prompt is cool enough, but let's chain some prompts together with some expansion. In this query, we'll prompt for a list of 5 cities, then split the comma separated response and normalize into 5 rows, then use a different prompt that includes the values ($response$) from the first prompt.
prompt "give me a list of 5 cities on earth, comma separated. like Paris, Los Angeles,etc."
|| split response ","
|| normalize response
|| prompt "what is the distance in miles to $response$ from San Francisco. Respond only with the numeric value. So if the answer is 3000 miles, respond with just 3000, no miles, commas or other punctuation or units of measurement"
Seed prompts from web content
We can manually fill in the prompt, or generate one/many from a previous set of results. For example, let's get all the headlines from the Hacker News homepage, then ask OpenAI to create a haiku based on each headline. Notice the $headline$ token in the prompt which allows us to create dynamic, previous stage dependent prompts.
open https://news.ycombinator.com/news
|| filter "(nodeName == 'A' and parentElement.attributes.class == 'titleline')"
|| rename innerText headline
|| prompt "Write a haiku about the following headline: $headline$"
Note: This query will have outbound requests throttled by domain policies, which defaults to 1 request per second per domain. This is also the throttle for the OpenAI API as of this blog post, so all good there!
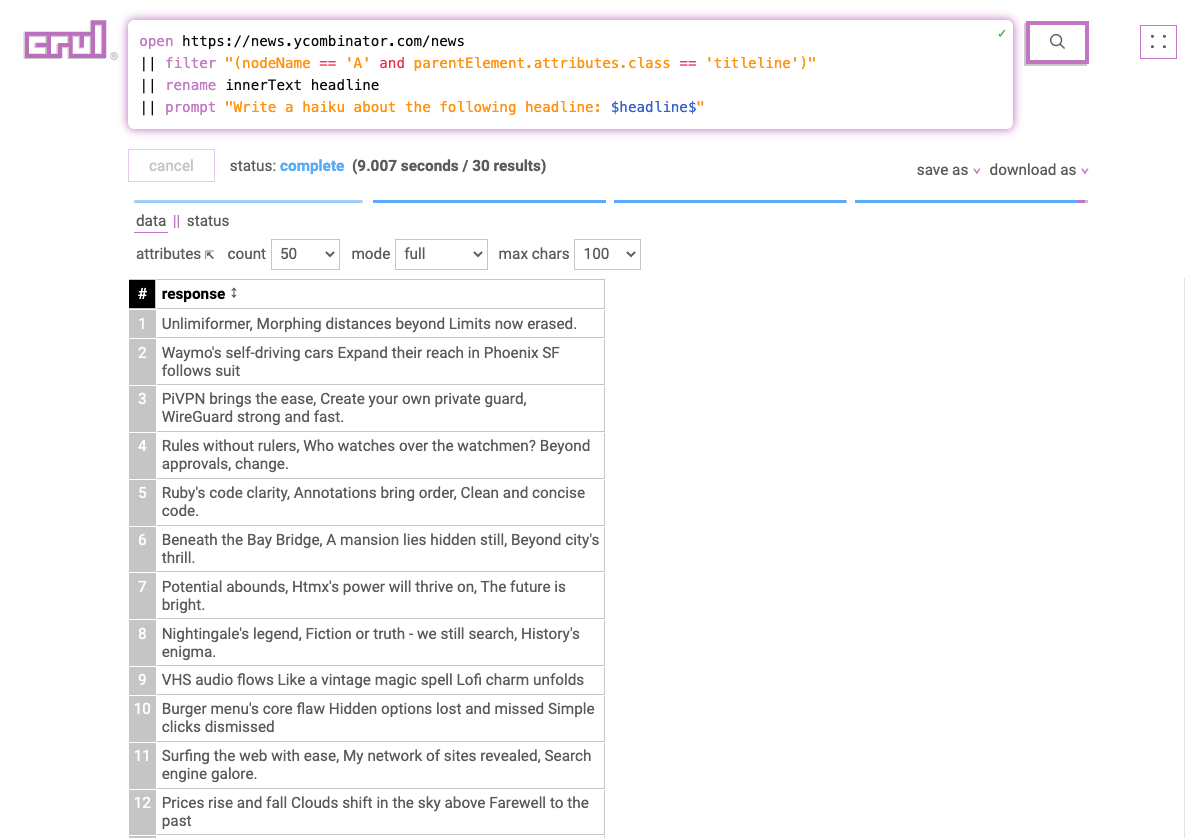
That's kind of cute! Let's try a more complex prompt and translate each title to French.
Translate web content
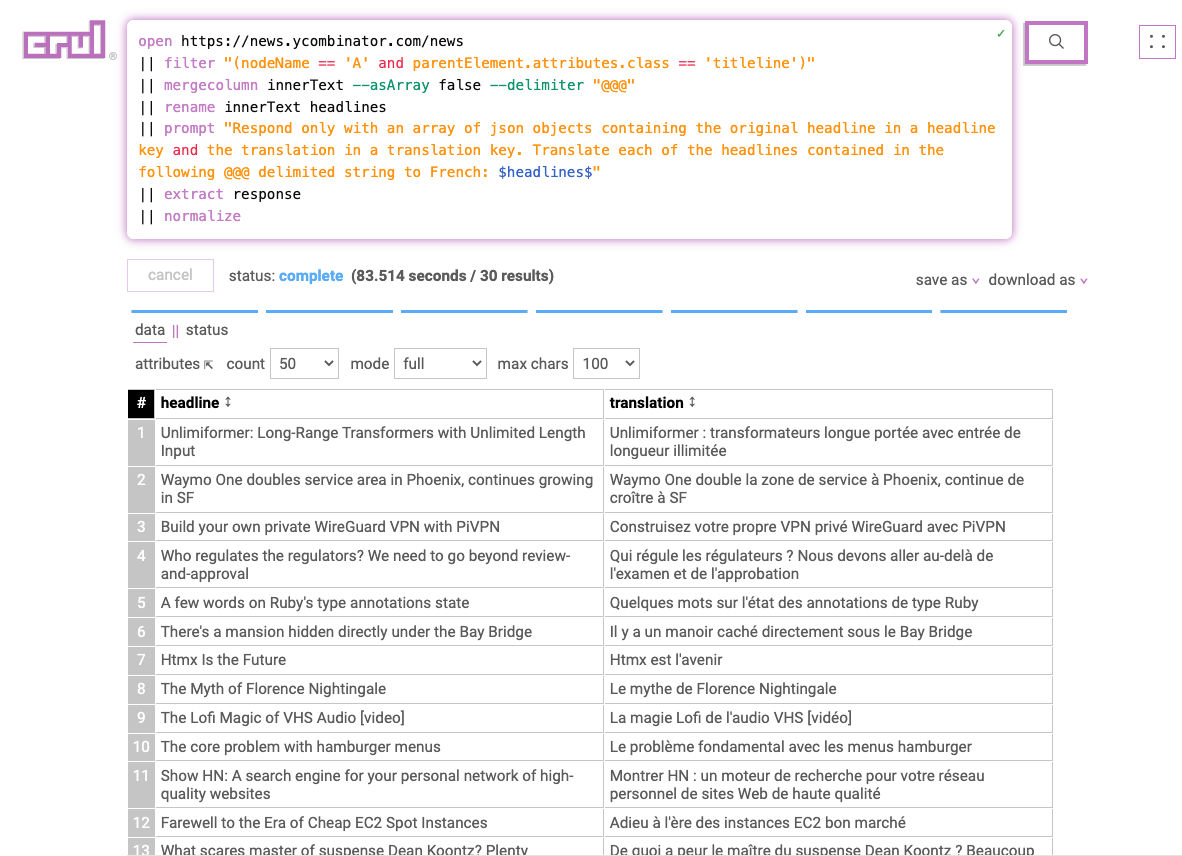
What's different about the next query is that we'll merge the headlines into a single row containing a @@@ delimited string to pass into a single request. This isn't neccessary, however it reduces the number of requests we make in the prompt commands stage.
The last two stages (extract and normalize) of the query will extract the JSON response and expand it into rows.
For similar queries, you will need to write your prompt accordingly to let the model understand the data structure you are providing it with.
open https://news.ycombinator.com/news
|| filter "(nodeName == 'A' and parentElement.attributes.class == 'titleline')"
|| mergecolumn innerText --asArray false --delimiter "@@@"
|| rename innerText headlines
|| prompt "Respond only with an array of json objects containing the original headline in a headline key and the translation in a translation key. Translate each of the headlines contained in the following @@@ delimited string to French: $headlines$"
|| extract response
|| normalize
Using different models
The current prompt command defaults to OpenAI's gpt-3.5-turbo model. To override, see the prompt command's --prompt.model flag.
Summary
Have fun playing with API and web content as seeds for LLM prompts! The possiblities are endless, and crul is great tool for quickly trying out new ideas, and creating ML powered workflows.
Possible next steps using crul?
Schedule the query and export the results to a data store of your choice to automate a workflow.
Use the responses as inputs to another API request.
Download the results to CSV/JSON for further processing elsewhere.
We're working on a few improvements to transform web content into JSON friendly strings. Until then, you may run into classic (annoying) issues with string escaping in the --data object.
Please let us know if you run into any issues!
Pretty cool no? Or terrifying, you decide.
Template explanation
The Prompt OpenAI template is essentially the query below. It's a pretty standard authenticated API request using the crul language, where we set headers for Content-Type and Authorization and provide a data payload.
To run this query, you'll need to remplate the $template...$ tokens with explicit values or tokens of your own. For example $template.apiKey$ could be replaced with $CREDENTIALS.openai$.
api post https://api.openai.com/v1/chat/completions
--headers '{
"Content-Type": "application/json",
"Authorization": "Bearer $template.apiKey$",
}'
--data '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "$template.prompt$"}],
}'