OpenAI assisted Spotify playlist curation
Let's take a look at how we can use the Spotify API to categorize songs into different types of playlists with the help of OpenAI's evaluation of a track's lyrics, and audio features.
Our initial tracks
To keep things simple, we'll start with a pair of playlists that we can use as an initial list of tracks to further categorize. This is also a demonstration of how you can import files into crul as seeds for API calls or other processing.
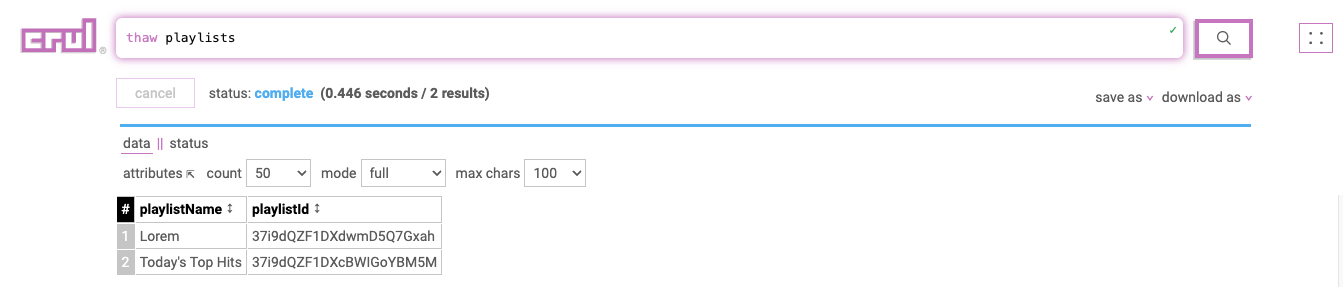
| playlistName | playlistId |
|---|---|
| Lorem | 37i9dQZF1DXdwmD5Q7Gxah |
| Today's Top Hits | 37i9dQZF1DXcBWIGoYBM5M |
OR (copy pasteable)
playlistName, playlistId
Lorem, 37i9dQZF1DXdwmD5Q7Gxah
Today's Top Hits, 37i9dQZF1DXcBWIGoYBM5M
We'll need to save and upload this playlists.csv file to crul's cellar. Then we can thaw it into our query pipeline.
thaw playlists
Retrieving our intial tracks
Want to see the full query first? Here it is, we'll explain it step by step in the rest of the post.
We'll first need a set of Spotify credentials. Now we'll thaw our playlists.csv file and use the api command to list the number of tracks in these two playlists. Finally we'll normalize the results using the normalize command.
thaw playlists
|| api get https://api.spotify.com/v1/playlists/$playlistId$/tracks
--credentials.oauth spotify
--pagination.next next
|| normalize items
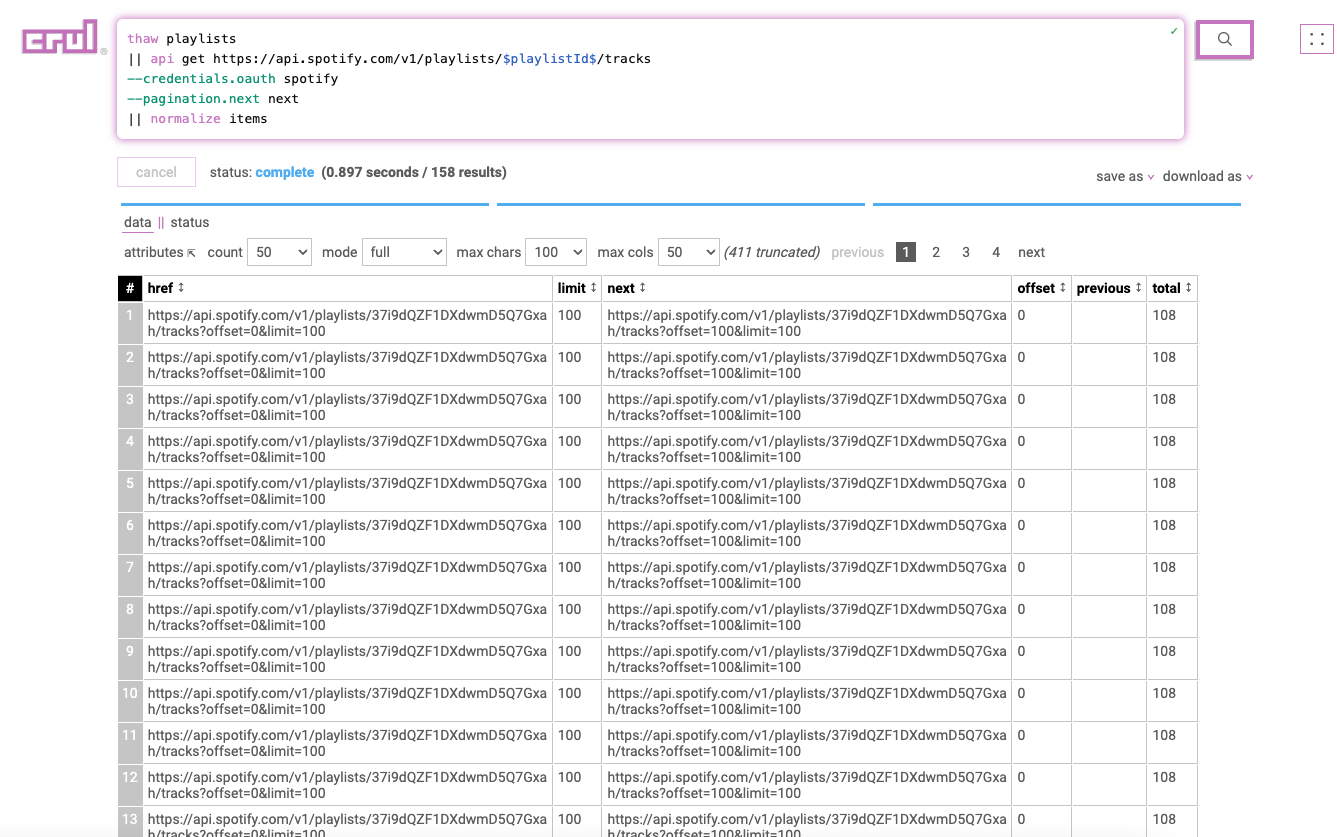
What's cool about this example is the demonstration of expansion, where each line of the thawed playlists.csv file runs the api command, as well as the oauth flag for OAuth Authentication, and the pagination capabilites of the api command.
Batching song ids
Some APIs support batch requests, where we can make a request with a batch of identifiers instead of making a request per identifier. Crul can handle both options, here we'll rename our id to trackId, and merge them all together into a comma delimited string using the mergecolumn command.
...
|| rename track.id trackId --labelStage "allTracks"
|| table trackId
|| mergecolumn trackId --maxRows 100 --asArray false
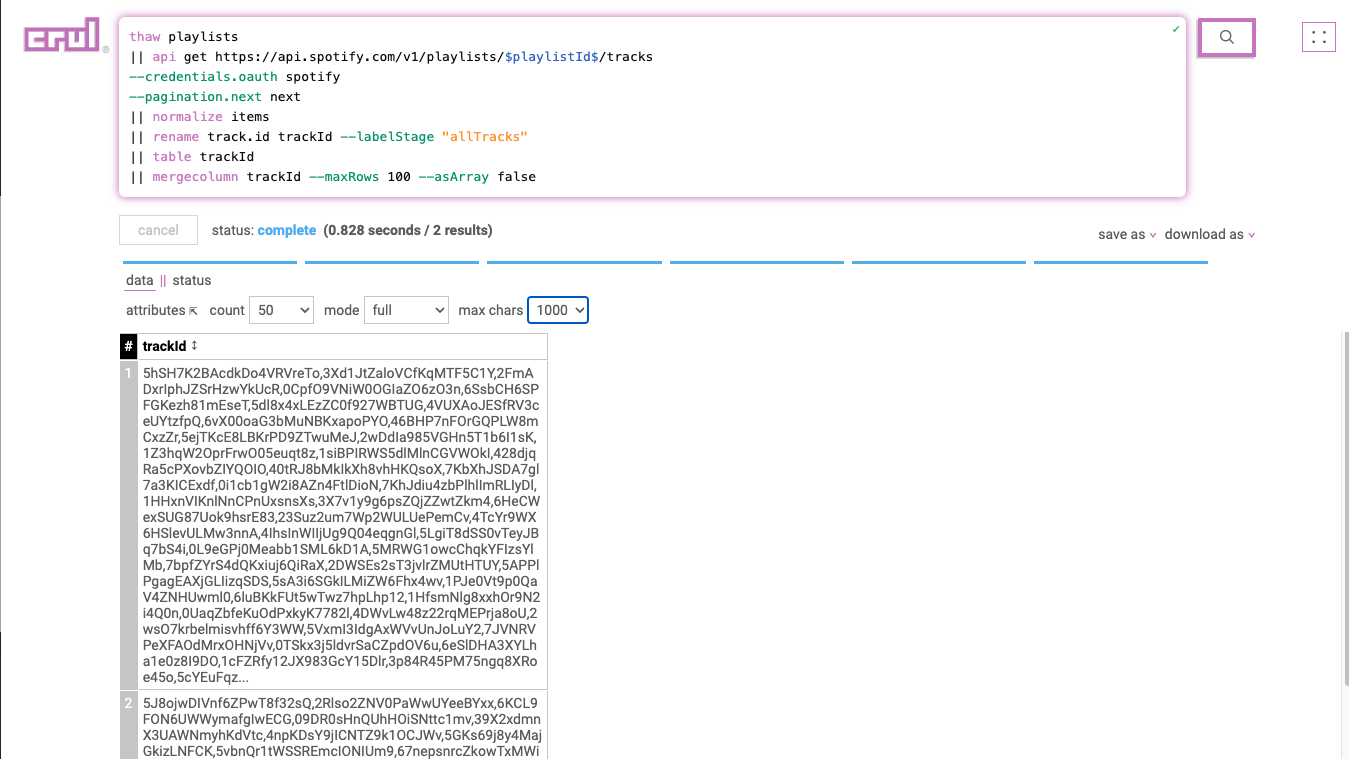
The Spotify API has a limit of 100 tracks per request, hence the --maxRows 100 flag.
Note the --labelStage allTracks flag which allows us to label that specific stage to access or join to later.
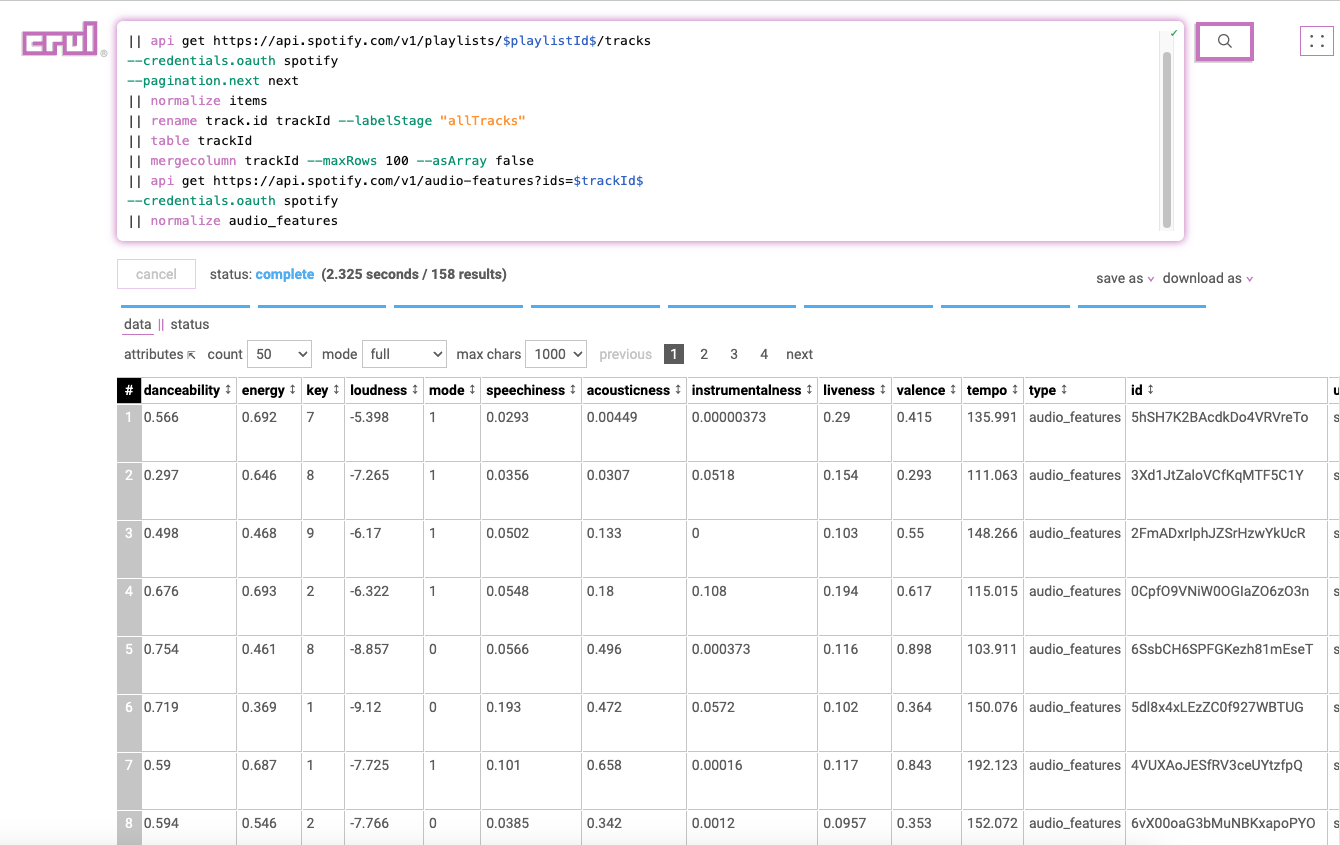
Retrieving the audio features of each track
Spotify provides an excellent set of metadata for each track. These metadata fields include semi subjective values like energy, accousticness, danceability, and others, as well as more empirical values like key, tempo, time signature, etc. Let's enrich each track with these audio features.
...
|| api get https://api.spotify.com/v1/audio-features?ids=$trackId$
--credentials.oauth spotify
|| normalize audio_features
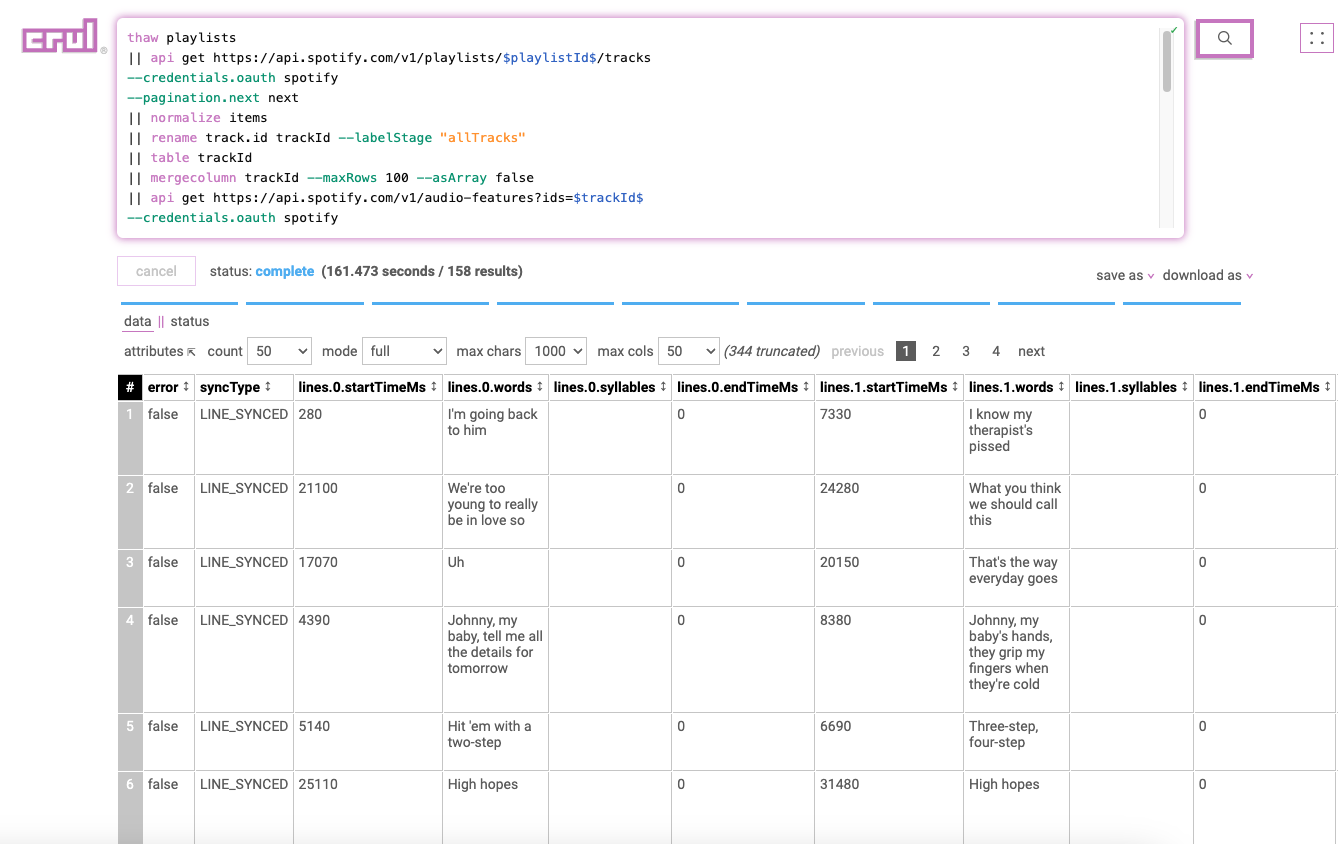
Enriching each track with lyrics
As of this post, the Spotify API does not expose a way to retrieve lyrics, however there are a number of APIs that do. We're using a simple one that only needs a Spotify track id. Nice!
...
|| api get https://spotify-lyric-api.herokuapp.com/?trackid=$id$ --enrich
|| filter "(syncType != null)"
We'll do a quick filter to drop any tracks without lyrics.
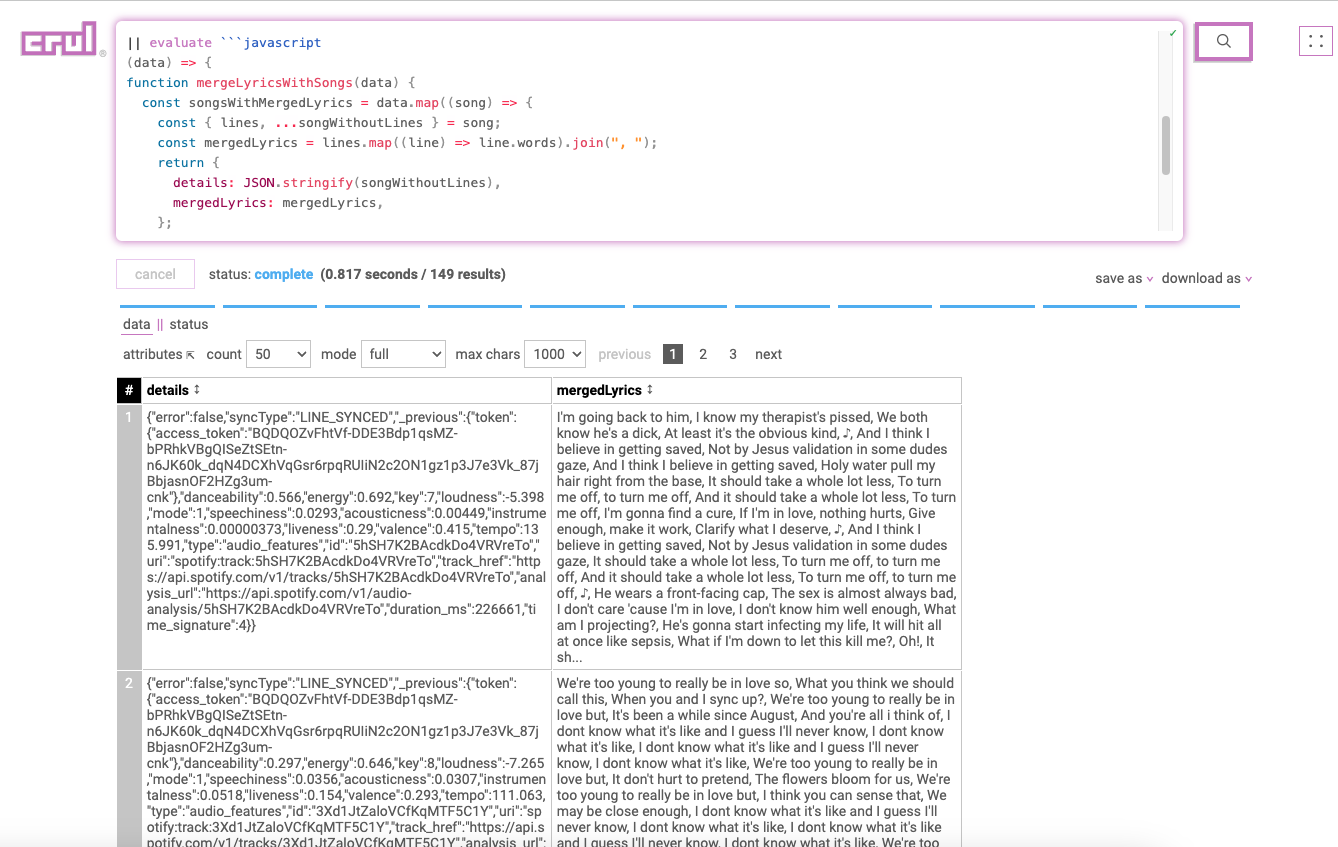
Merging the lyrics
The lyrics that we get back from the lyrics API are well formatted but a little tricky for us to use with OpenAI. We instead want each line joined into a comma delimited string. It's possible to do this using the crul query language only, but let's write a simple JavaScript expression that we'll run using the evaluate command instead.
Sometimes it's easier to just write a little code!
...
|| evaluate ```javascript
(data) => {
function mergeLyricsWithSongs(data) {
const songsWithMergedLyrics = data.map((song) => {
const { lines, ...songWithoutLines } = song;
const mergedLyrics = lines.map((line) => line.words).join(", ");
return {
details: JSON.stringify(songWithoutLines),
mergedLyrics: mergedLyrics,
};
});
return songsWithMergedLyrics;
}
return mergeLyricsWithSongs(data);
}
```
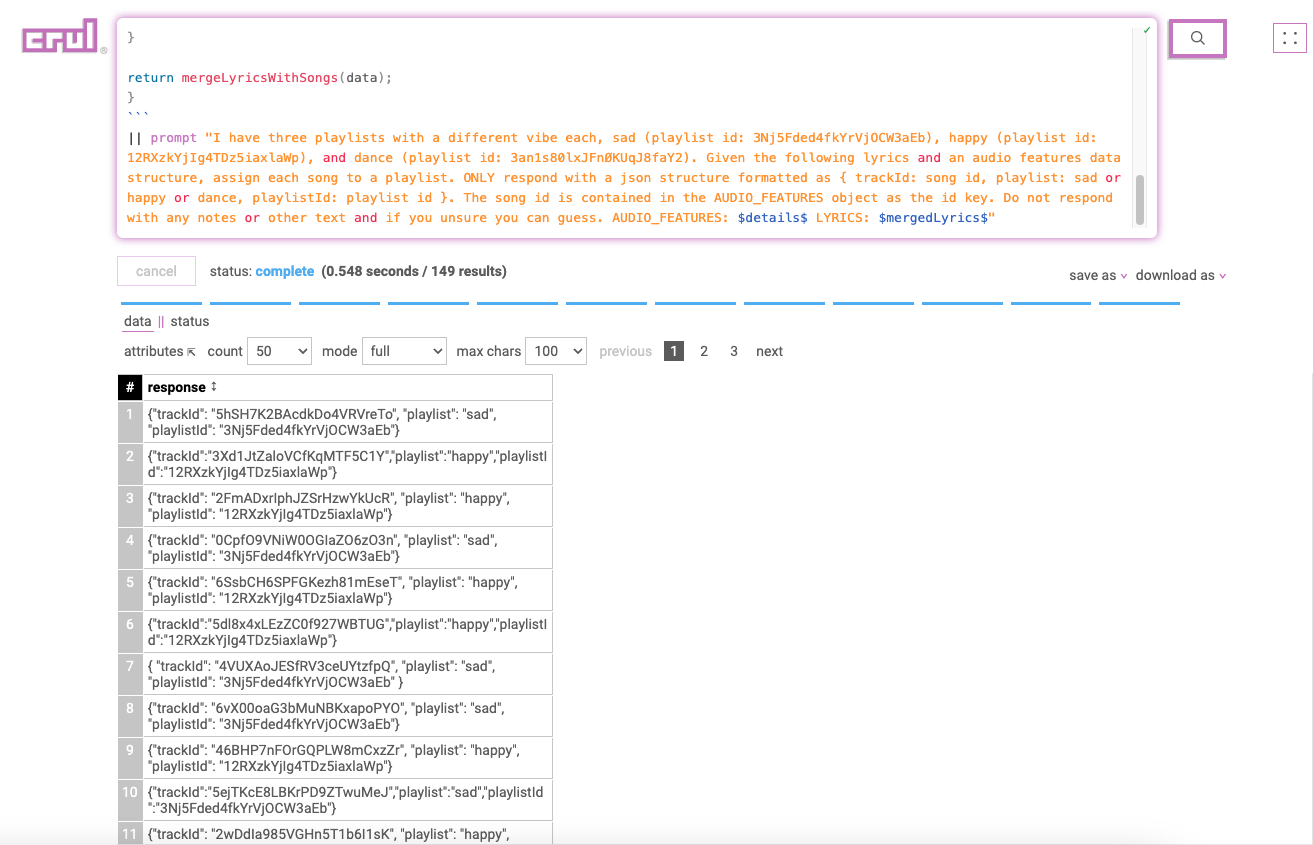
Categorizing our songs into a playlist with OpenAI
We'll run each song and its metadata/lyrics through OpenAI with a prompt that creates a JSON structure with each song assigned to a matching playlist.
Notice the $details$ and mergedLyrics tokens that we are passing into our prompt in order to provide the GPT with our freshly retrieved API data.
This allows us to get past GPT limitations relating to training data cut off dates.
...
|| prompt "I have three playlists with a different vibe each,
sad (playlist id: 3Nj5Fded4fkYrVjOCW3aEb),
happy (playlist id: 12RXzkYjIg4TDz5iaxlaWp),
dance (playlist id: 3an1s80lxJFnØKUqJ8faY2).
Given the following lyrics and an audio features data structure, assign each song to a playlist.
ONLY respond with a json structure formatted as:
{ trackId: song id, playlist: sad or happy or dance, playlistId: playlist id }.
The song id is contained in the AUDIO_FEATURES object as the id key.
Do not respond with any notes or other text and if you unsure you can guess.
AUDIO_FEATURES: $details$ LYRICS: $mergedLyrics$"
Note: Prompts can be a little non deterministic. You may need to tweak it if you are seeing certain errors pop up, or filter the results to get rid of anything bad.
Cleaning up and enriching our results
Lastly, let's clean up and enrich our results bu first extracting the stringified JSON from our response column. joining the track details from earlier in our query with the playlist curation, and finally tableing the columns we are most interested in.
...
|| extract response
|| join trackId allTracks
|| table trackId track.name track.artists.0.name playlist playlistId mergedLyrics
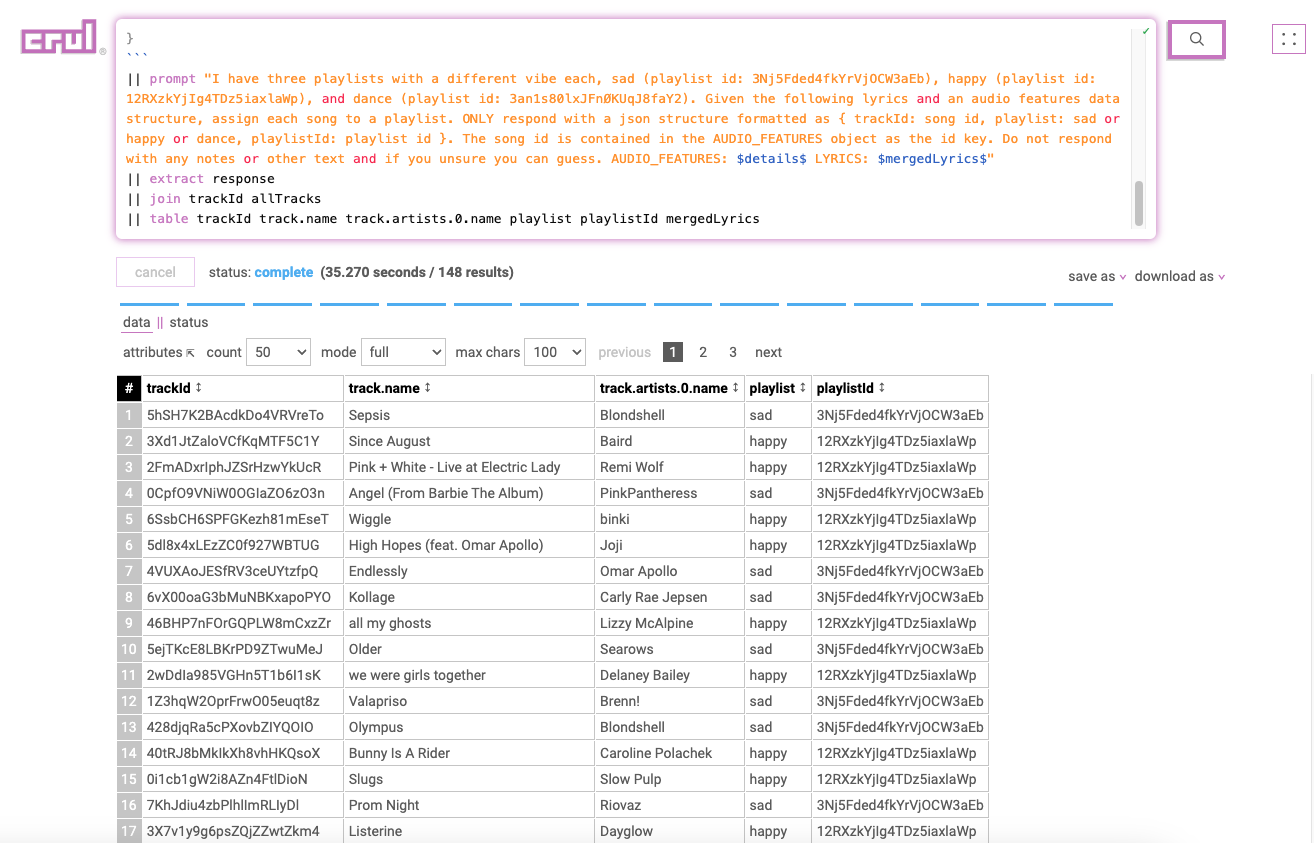
Pretty cool no? And so easy to tweak, whether that's what goes into prompt, the prompt itself, or anything else!
What next?
The original goal was to push these directly into my sad/happy/dance playlists, but we'll need to a do a bit of work to support the Spotify API endpoints that access user resources. Not too hard to do with your own script though!
Additionally we could scheduled and diff this query and populate an S3 bucket or other third-party store for further processing, we could populate a vector database or use any part of this data set as a seed for a semi synthetic data set...
Let us know what you come up with!
Join our Community
Come hang out and ask us any questions. Some of the features and fixes in this release come from your requests!
Full query
Below is the full query, it assumes you have configured a credential called spotify and have uploaded a playlists.csv file.
thaw playlists
|| api get https://api.spotify.com/v1/playlists/$playlistId$/tracks
--credentials.oauth spotify
--pagination.next next
|| normalize items
|| rename track.id trackId --labelStage "allTracks"
|| table trackId
|| mergecolumn trackId --maxRows 100 --asArray false
|| api get https://api.spotify.com/v1/audio-features?ids=$trackId$
--credentials.oauth spotify
|| normalize audio_features
|| api get https://spotify-lyric-api.herokuapp.com/?trackid=$id$ --enrich
|| filter "(syncType != null)"
|| evaluate ```javascript
(data) => {
function mergeLyricsWithSongs(data) {
const songsWithMergedLyrics = data.map((song) => {
const { lines, ...songWithoutLines } = song;
const mergedLyrics = lines.map((line) => line.words).join(", ");
return {
details: JSON.stringify(songWithoutLines),
mergedLyrics: mergedLyrics,
};
});
return songsWithMergedLyrics;
}
return mergeLyricsWithSongs(data);
}
|| prompt "I have three playlists with a different vibe each, sad (playlist id: 3Nj5Fded4fkYrVjOCW3aEb), happy (playlist id: 12RXzkYjIg4TDz5iaxlaWp), and dance (playlist id: 3an1s80lxJFnØKUqJ8faY2). Given the following lyrics and an audio features data structure, assign each song to a playlist. ONLY respond with a json structure formatted as { trackId: song id, playlist: sad or happy or dance, playlistId: playlist id }. The song id is contained in the AUDIO_FEATURES object as the id key. Do not respond with any notes or other text and if you unsure you can guess. AUDIO_FEATURES: $details$ LYRICS: $mergedLyrics$" --enrich
|| extract response
|| join trackId allTracks
|| table trackId track.name track.artists.0.name playlist playlistId mergedLyrics