Quickstart 2: Retrieving comments from top posts on Hacker News
Introduction
For this query, we are looking to build a data set of comments from the top posts on Hacker News. While we could use the Hacker News API, building the data set through a query is a great demonstration of the crul query language.
In this query, we'll start by using the open command to open the Hacker News homepage, render content, and transform the rendered page into an enriched, tabular data set of all the elements on the page.
Then, we'll filter the page down to links to post comments, and finally, we'll use the open command to open each link and transform the pages into a merged data set, which we can filter for individual comments.
Stage 1: Opening the Hacker News homepage
open https://news.ycombinator.com/news
The first stage will open the Hacker News site and process the page into a tabular structure. Think of crul as browser that is opening this page and rendering the content, fulfilling network requests, etc., then converting that rendered content a tabular format.
Stage 2: Filtering for comment links
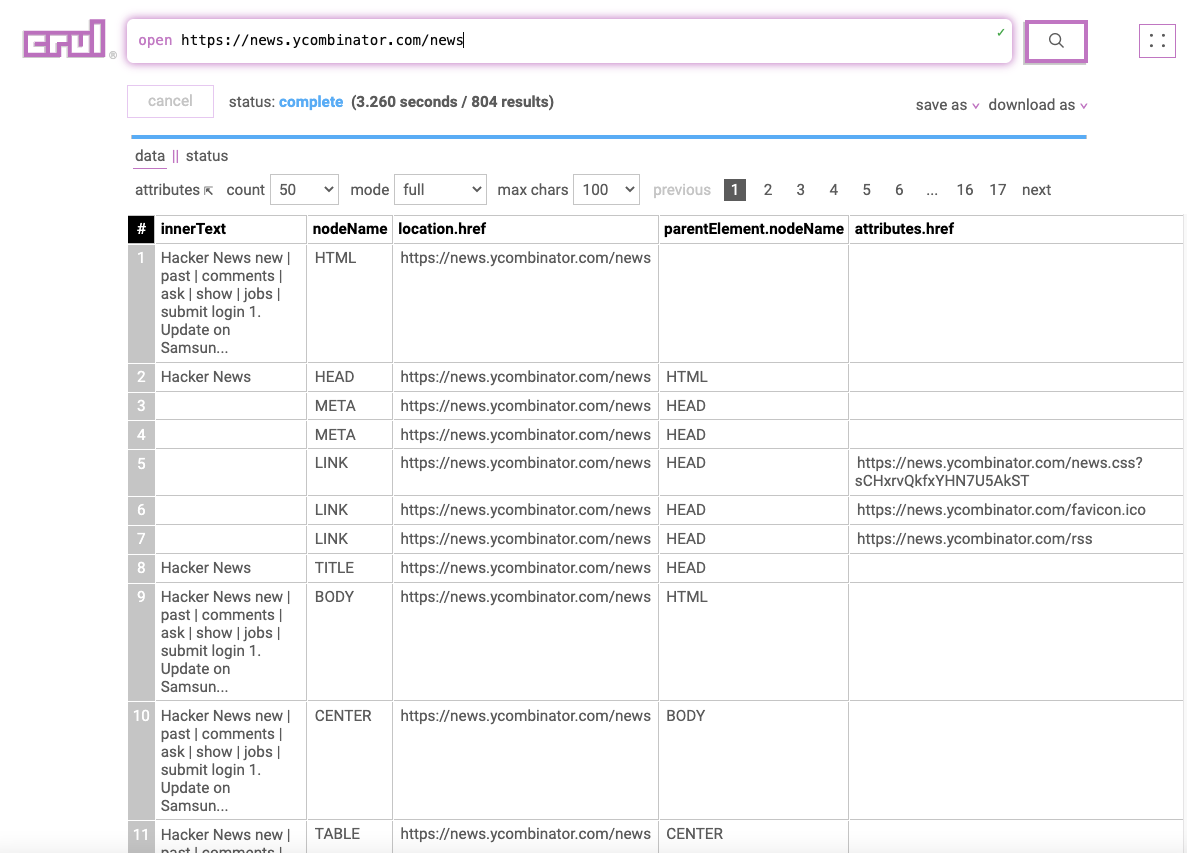
open https://news.ycombinator.com/news
|| find comments
In the second stage we will use the find command to find the keyword comments in the results. This helps to narrow down our data set to only rows that contain the string comments somewhere in the row values.
Stage 3: Filtering for comment links
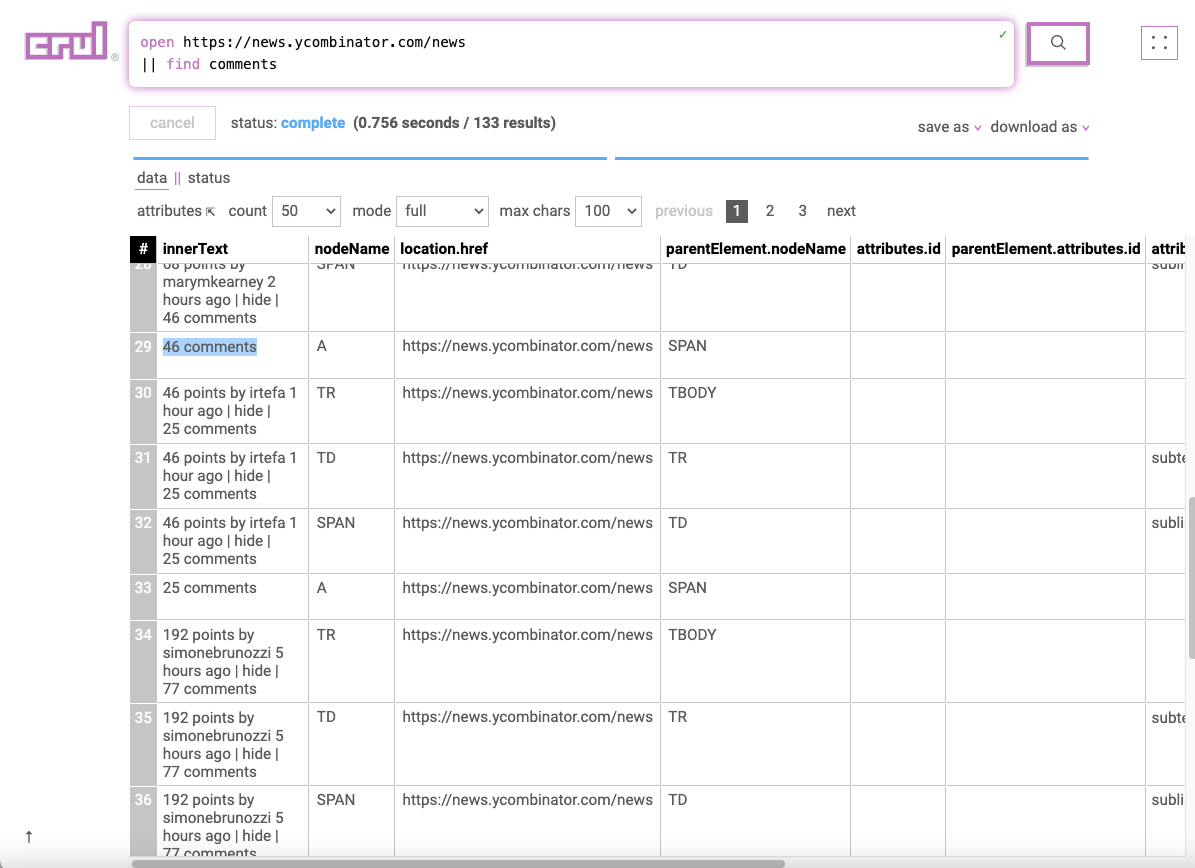
open https://news.ycombinator.com/news
|| find comments
|| filter "(nodeName == 'A') and (parentElement.attributes.class == 'subline')"
In the third stage we will use the filter command to run a filtering expression that narrows down our result set to just links to comment sections. We now have a list of links to comments to pass into our next expanding stage.
Stage 4: Opening comment links
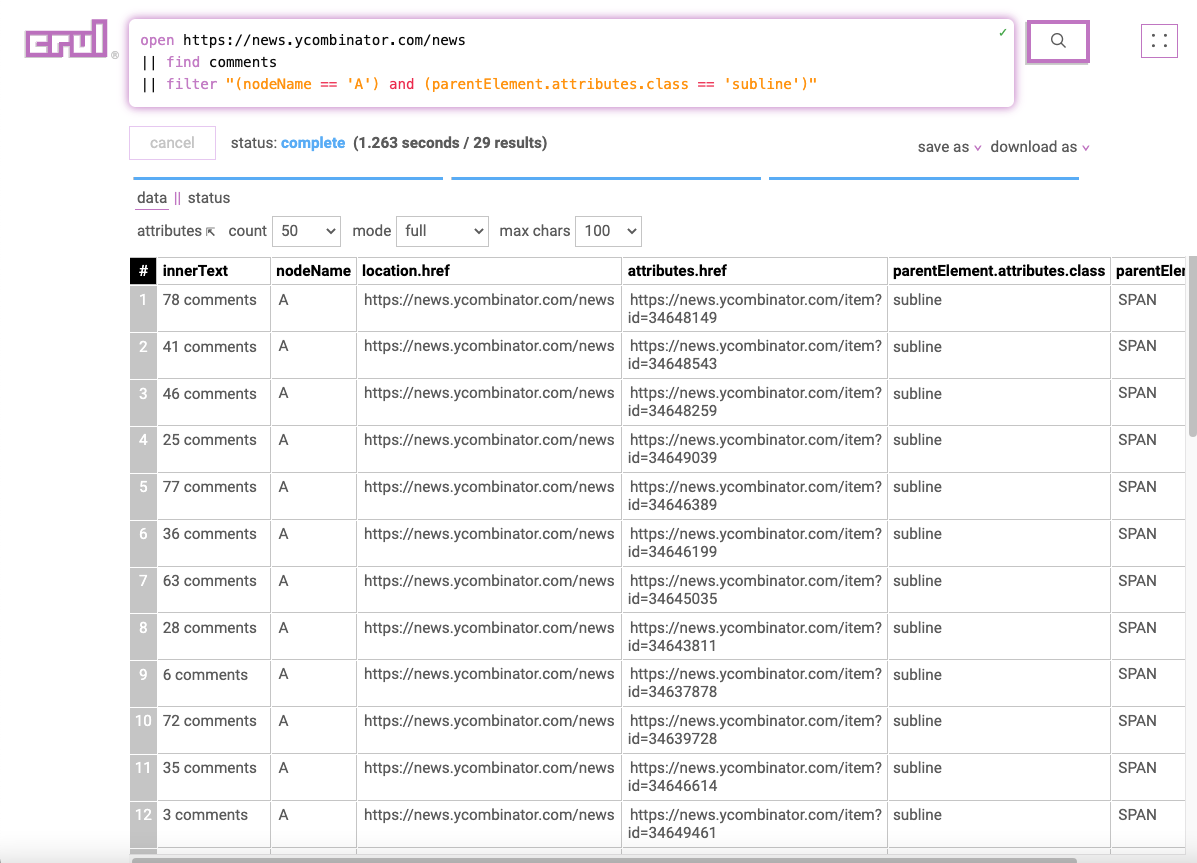
open https://news.ycombinator.com/news
|| find comments
|| filter "(nodeName == 'A') and (parentElement.attributes.class == 'subline')"
|| open $attributes.href$
In the fourth stage, we will use our list of links to comments with the open command to open each link asynchronously (throttled/limited by domain policy and available browser workers). This query will take a little bit longer to run as it makes the (throttled) requests and renders each page.
Notice the $attributes.href$ token (tokens are denoted by the $...$ syntax). This translates to plucking out the value contained in the attributes.href column for each row and replacing the $attributes.href$ token with it.
The results from each opened page will be merged into a single data set.
Stage 5: Filtering for comments
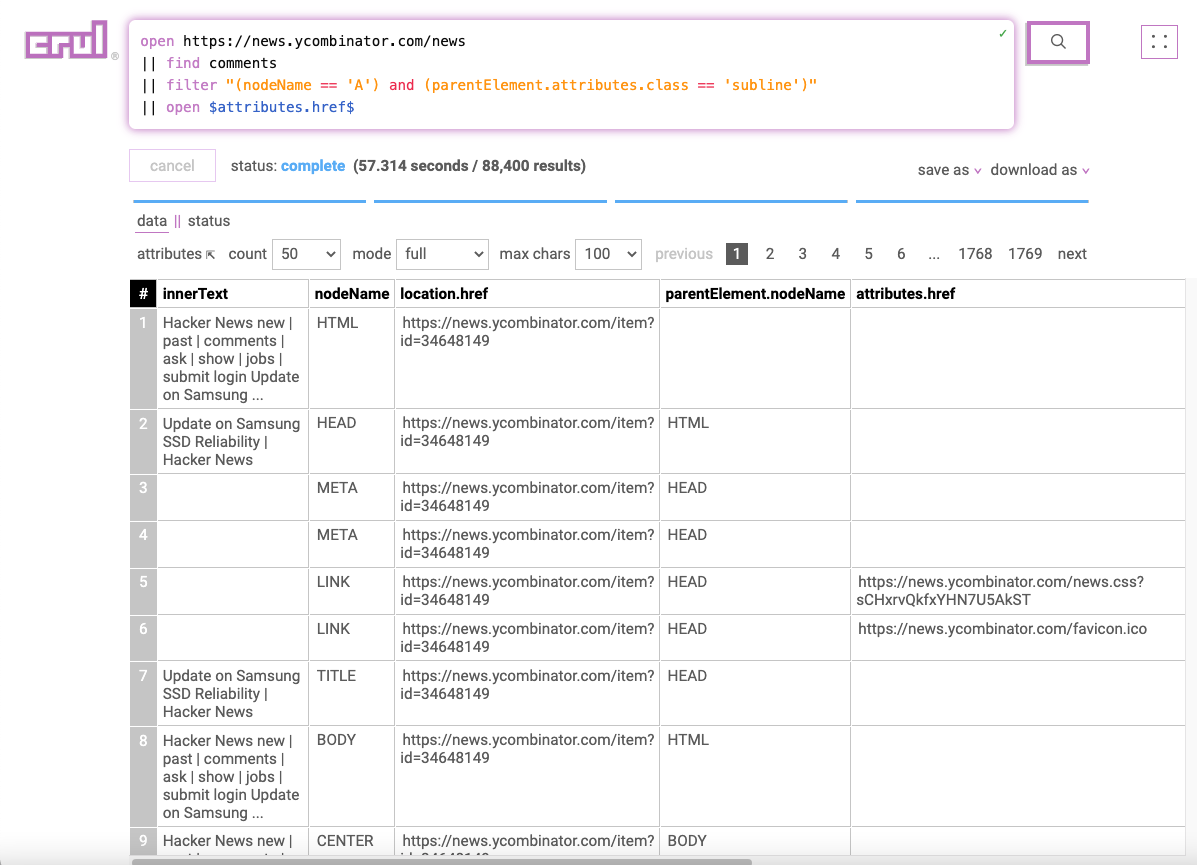
open https://news.ycombinator.com/news
|| find comments
|| filter "(nodeName == 'A') and (parentElement.attributes.class == 'subline')"
|| open $attributes.href$
|| filter "(attributes.class == 'comment')"
We and then use the filter command on the results to only include elements on the page that contain a comment. Finding the right filter expression can be a little bit of trial and error. See the how to find filters docs for some approaches.
We now have a list of most of comments from the top postings on Hacker News!
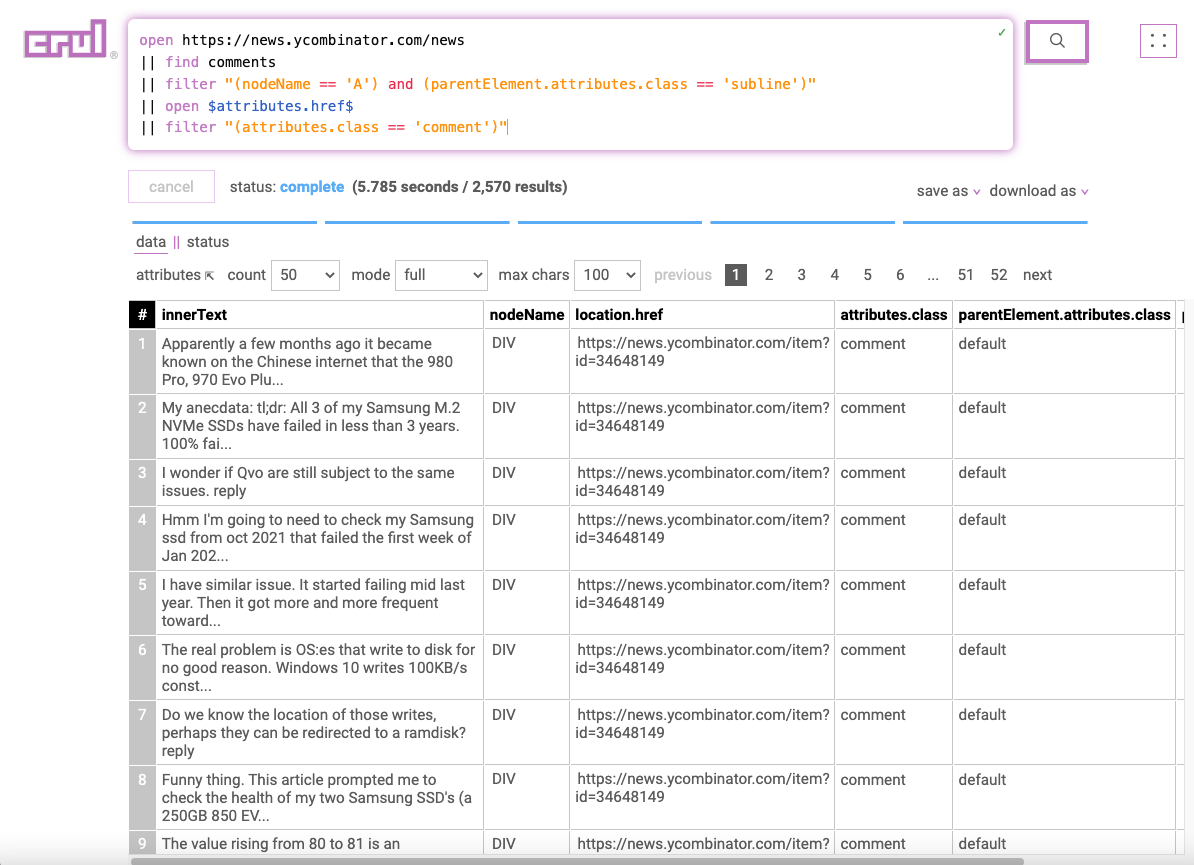
Note: There could be some missing comments due to possible expandable sections, but this is beyond the scope of this example!
Nice one!
You have run your first crul query! Pretty cool no? This only scratches the surface of the capabilities of crul. You can interact with web pages in a similar way, incorporate API keys and other credentials, send results to a data store with a single command, schedule queries, and more! If you would like a local copy of your query results, click on download as to save this as a CSV or JSON file.
If you haven't yet, try out the API focused quickstart!
To learn more about crul, check out the introduction and the getting started section next. Or check out our examples for additional queries!
Have fun and join us on slack or discord!
Contact us if you are interested in an Enterprise SaaS deployment of crul.