Building a data feed of GitHub issues to Cribl
Building a data feed from a query is a common use case of crul. In this example, we'll deploy a crul query that builds a dynamic data set from a REST API and delivers it to Cribl on a scheduled interval. We'll also explore how the diff command can be used to construct data feeds that only send new results.
Use case
We want to capture newly generated issues from a few Github repos and push those to Cribl once an hour.
Building our query
Our first step will be writing a query that gets back a set of issues. With the api command, this is straightforward.
api get https://api.github.com/repos/nodejs/node/issues?per_page=100
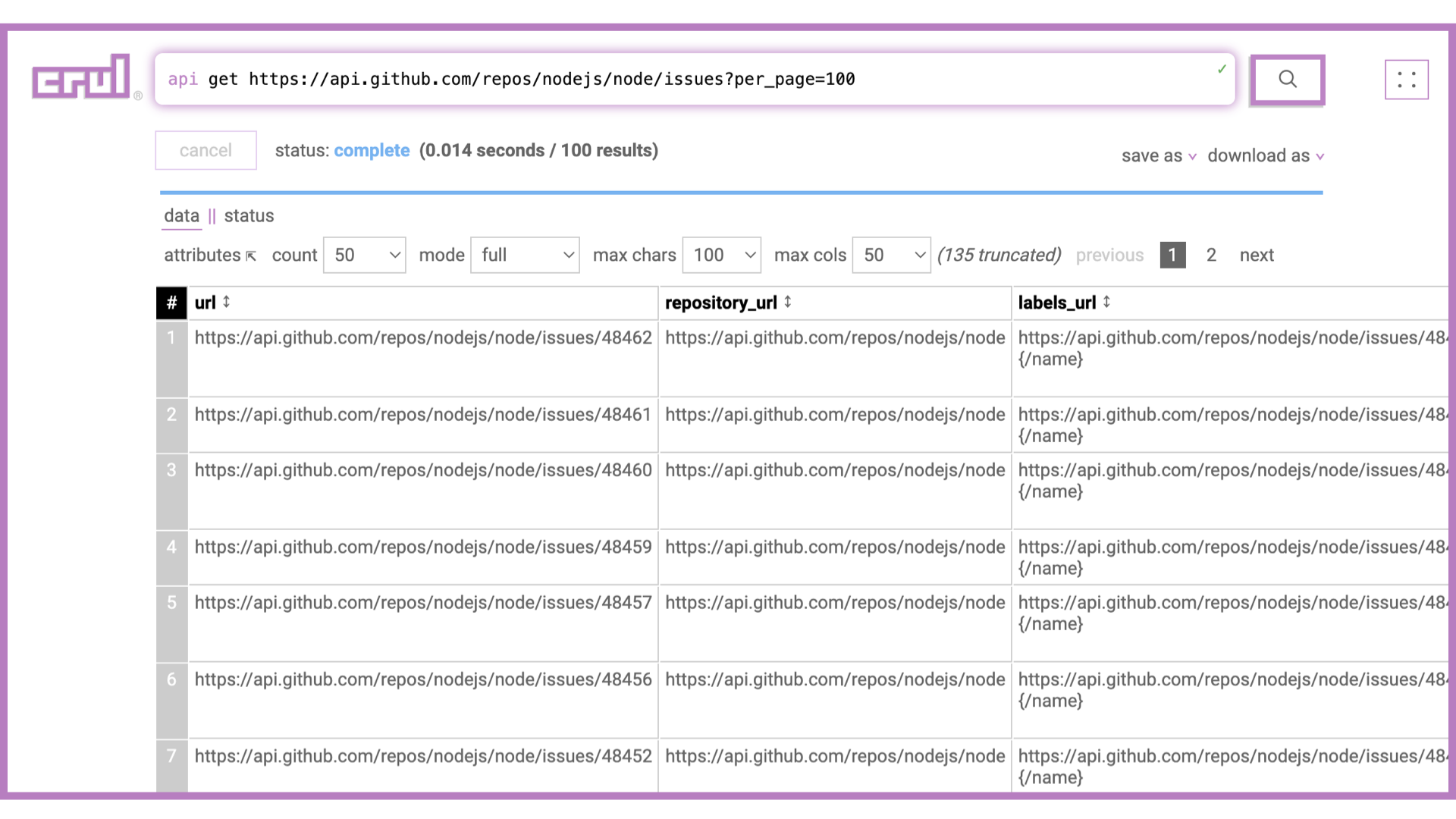
The api command is very powerful, and can handle authentication of various forms (including tokens, keys, OAuth, etc.), paginate, set checkpoints, set custom headers and dat payloads, and much more!
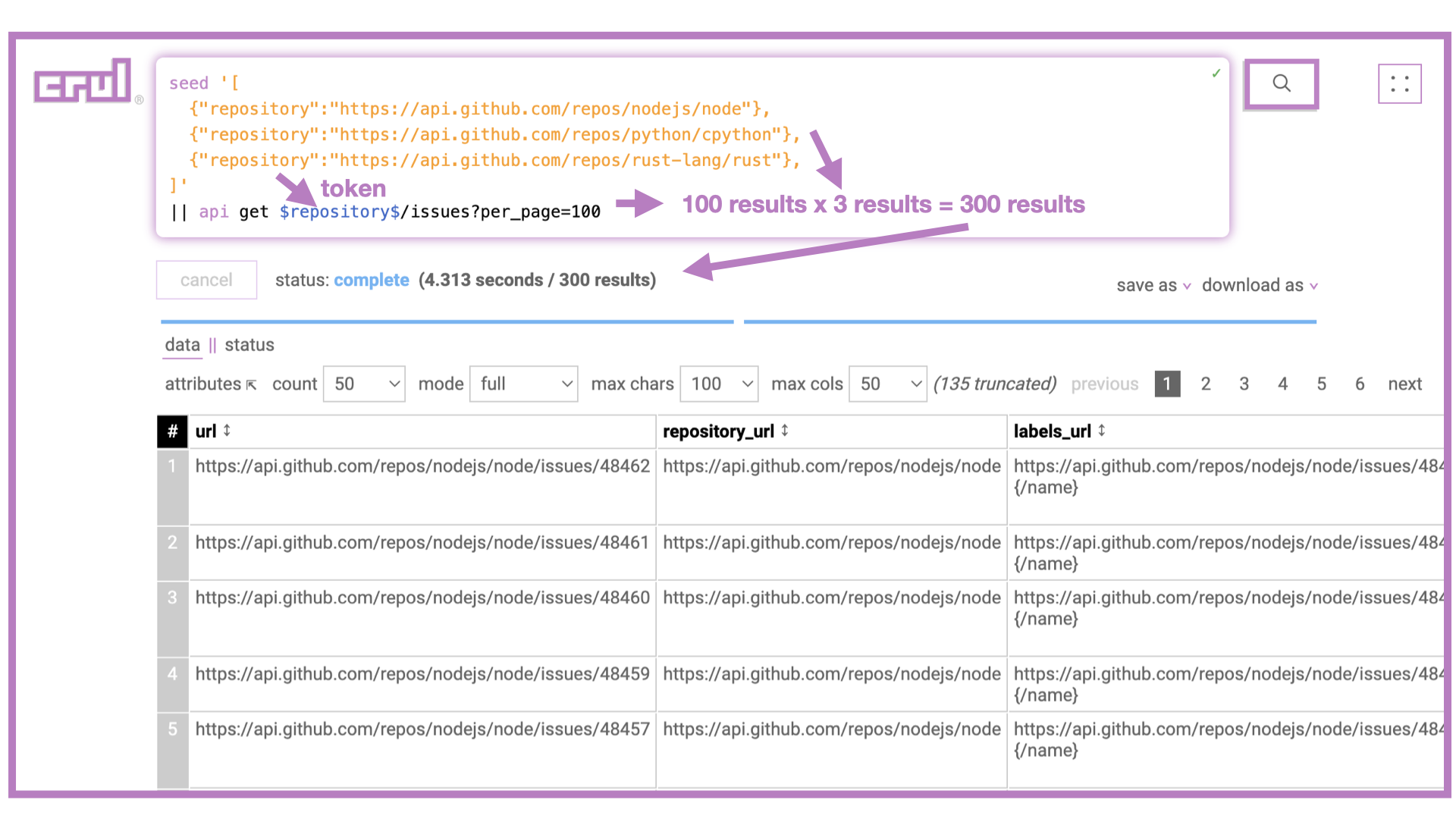
To now expand this query to issues from multiple repos we'll use the seed command with a few specific repositories. We could also dynamically fetch repos from a particular organization using an api request, or use the thaw command to use repositories previously described in a csv/json file and uploaded to the cellar.
seed '[
{"repository":"https://api.github.com/repos/nodejs/node"},
{"repository":"https://api.github.com/repos/python/cpython"},
{"repository":"https://api.github.com/repos/rust-lang/rust"},
]'
|| api get $repository$/issues?per_page=100
Great! Now we have the most recent 300 issues (max) from each the three provided repositories.
Advanced: Pagination
Many APIs return paginated responses, this means that not all results are available in a single request, the response however will include a pointer to the next set of results. This pointer could be a hash value, a page, an offset, or an explicit link. The crul api command can handle many types of pagination using the --pagination.* set of flags.
Advanced: Authentication
Many APIs require some form of authentication. This can be a token, an OAuth flow, or another mechanism. The api command is able to send requests with custom headers and data payloads, and also includes a --bearer flag among other auth related flags to support many forms of API authentication.
The oauth command also works for a number of supported OAuth providers, as well as custom Client Credentials flows.
Configuring a Store, Scheduling and Sending Incremental Diffs to Cribl
We now need to export this data set to Cribl and schedule it to run on a 1 hour interval. However, if we simply schedule the above query, we'll likely send many duplicate issues to Cribl as most repos will not create more than 100 issues per hour. This is why we'll need to use the diff command to only send over new issues that have not already been sent.
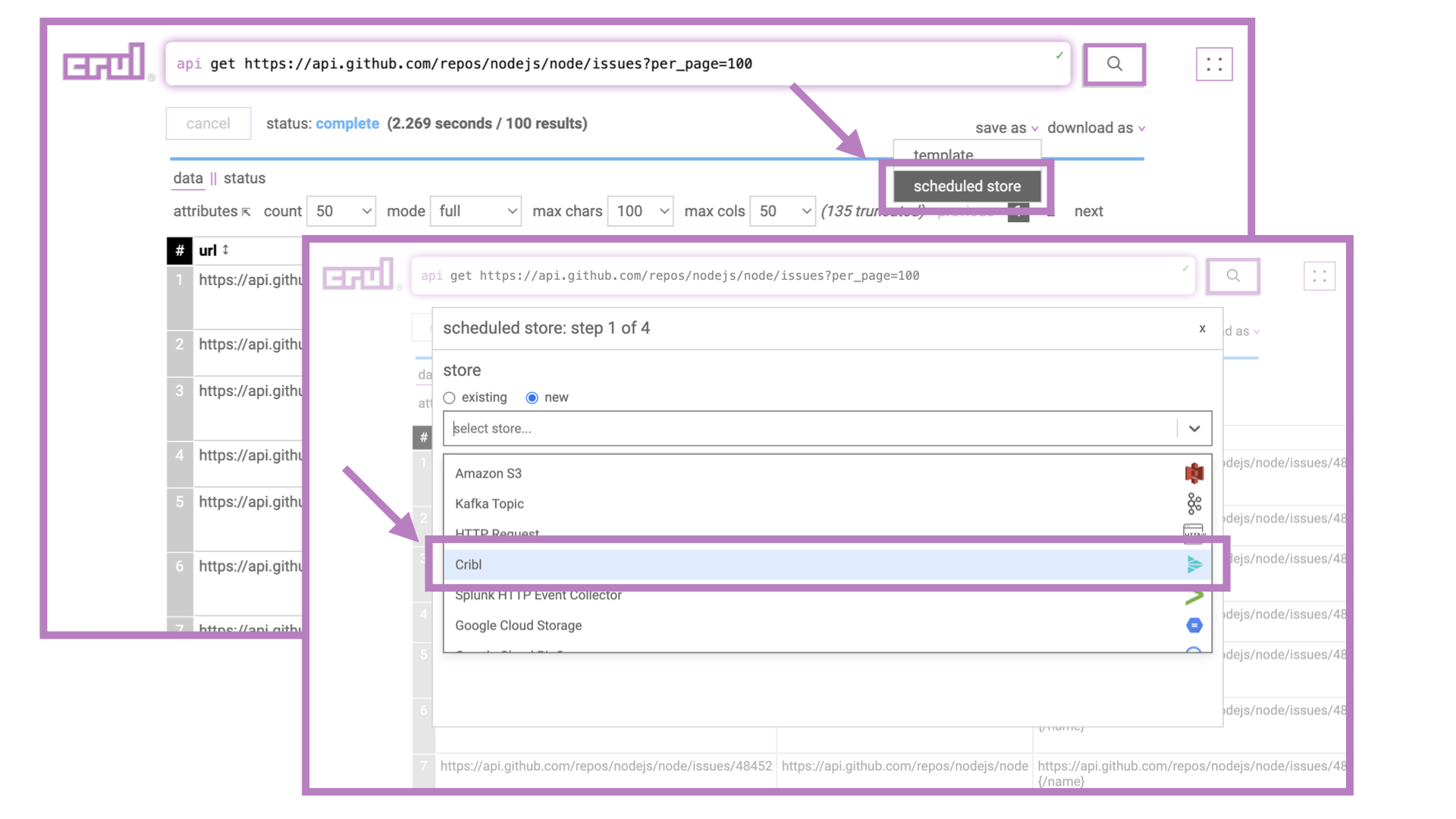
Since this diff/export/schedule step is so common, we can use crul's scheduled export wizard. Let's walk through each of the steps.
Step 1: Select a store or create a new one
The first step of the scheduled export wizard is to select a store, or configure a new one. Let's assume we are going to create a new one. If you have an existing store (possibly created by the export wizard previously?) you can simply select it from the dropdown.
Step 2: Select a schedule interval
Select a time interval for this query to run on. It will run shortly after creation and then on the set interval.

CAUTION! If you pick a short interval (less than 5 mins) you may run into issues with the crul cache. Ensure that stages in your query that you do not wish to be cached set the --cache flag to false. Example: api ... --cache false. When in doubt, set --cache false on all stages.
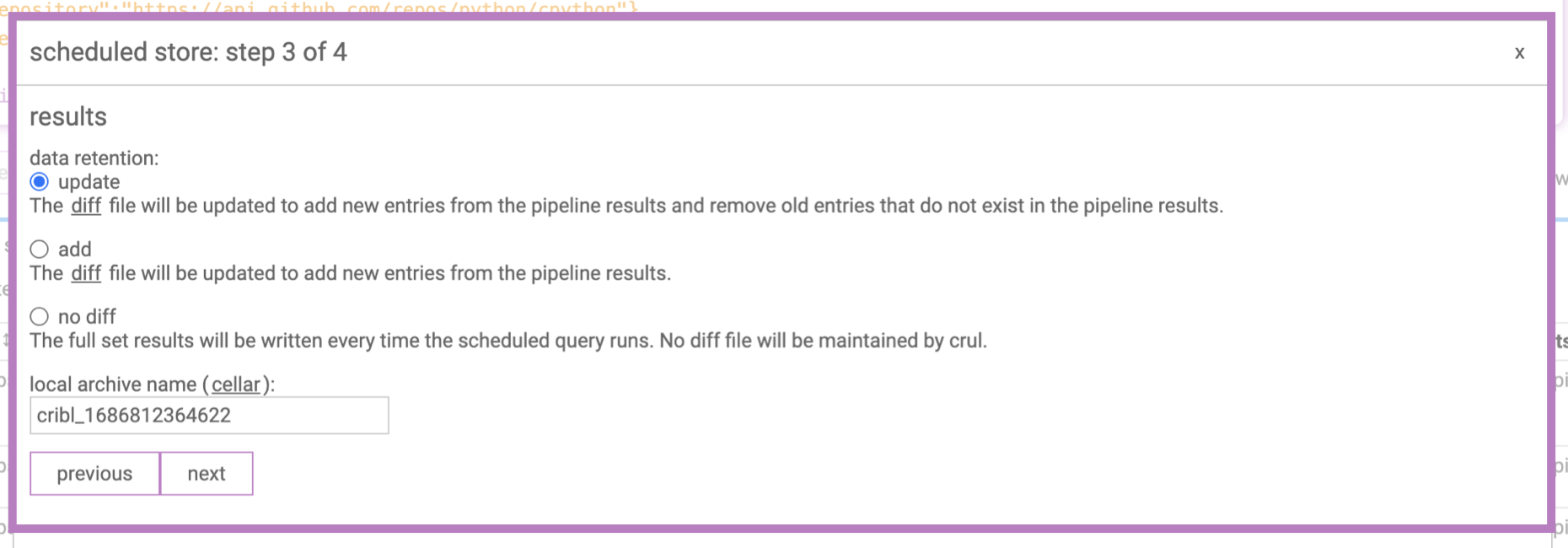
Step 3: Select a diff strategy
There are a few diff strategies.
Rotating diff
The rotating diff is the most commonly used diff strategy. It works by comparing the current diff file to the current results, then returning the results that do not exist in the diff file. Finally, it overwrites the diff file with all the current results, including ones that already existing in the diff file.
Content of old diff:
{"col": "value1"}
{"col": "value2"}
Results prior to diff command:
{"col": "value1"}
{"col": "value2"}
{"col": "value3"}
Results after diff command:
{"col": "value3"}
Contents of diff file after diff command:
{"col": "value1"}
{"col": "value2"}
{"col": "value3"}
Appending diff
Store ALL results and append new ones. This can lead to big, growing, diff files and is NOT recommended unless the results sets are small and/or your are cleaning the diff file regularly of older entries.
No diff
Send the whole set of results each time.
Step 4: Confirm and deploy!
Check that the details look correct and hit Submit to deploy the data feed. It will start running on a schedule.
Note that crul must be continually running for the scheduled queries to run. We recommend using the docker image as a long running service when creating data feeds.

Summary
We've now seen how simple it is to convert a query into a data feed, that populates one of 30+ destinations on a schedule, while maintaining a diff to ensure that only new result are sent over.
Any crul query can be turned into a feed using these steps! Have a web page that you would like turned into a data feed? No problem! Need to turn a REST API into a data feed? We got you!
Advanced
Looks like that wizard added a few stages to my query - how do those work?
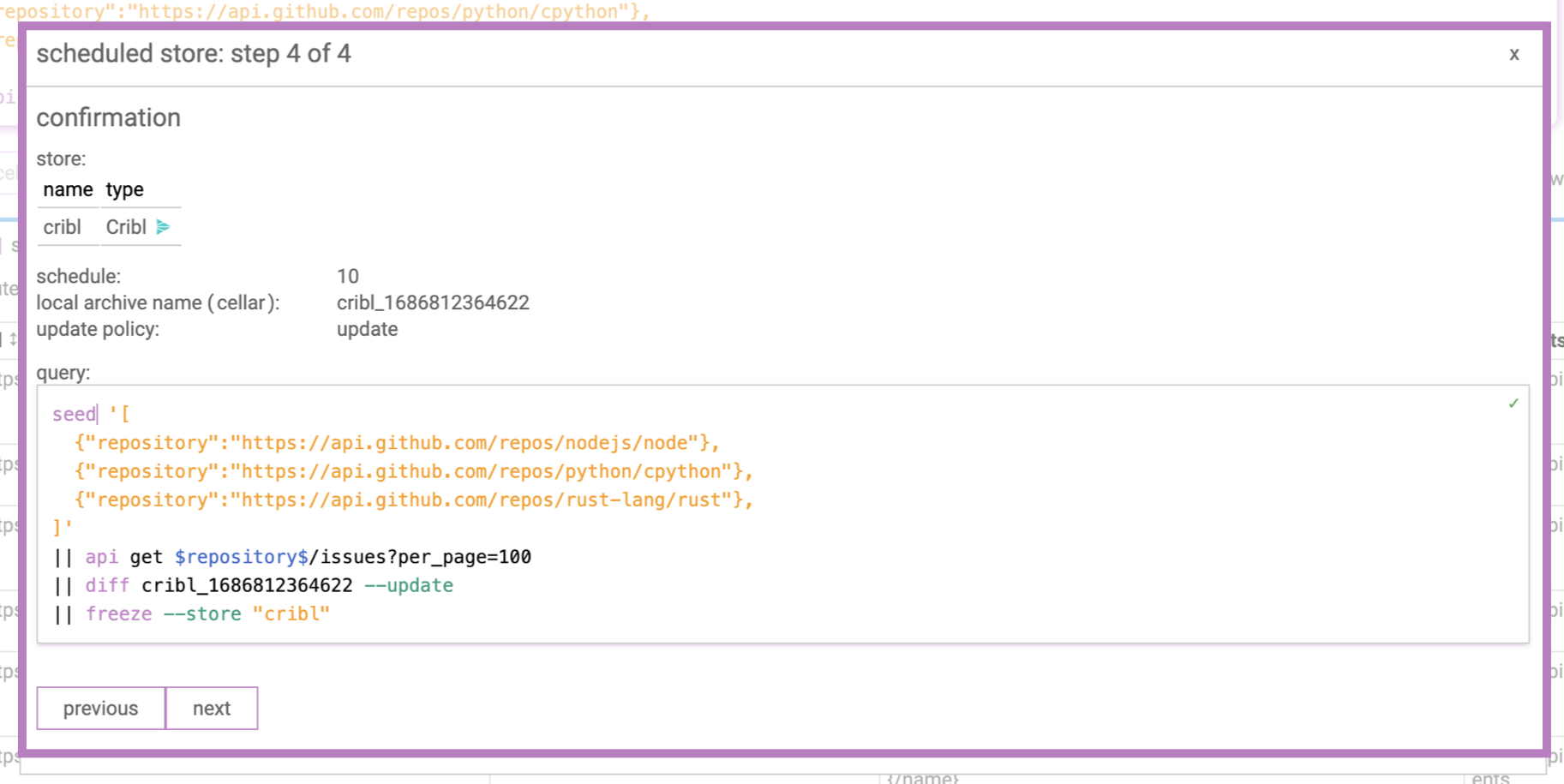
With the exception of the scheduling step, the wizard really only adds 2 stages to our data retrieval query.
The first added stage is the diff command, which compares the current results to previously sent results and only returns the new ones.
The second added stage is the freeze command, which delivers our data to a configured store. See exporting results.
Once you understand these commands, you can construct powerful data feeds yourself and schedule them manually, or just use the wizard!
Join our community
Come hang out and ask us any questions. Many of the features and fixes in crul come from our user requests!