Building a data feed of vector embeddings from Monday.com to Pinecone
Building a data feed from a query is a common use case of crul. In this example, we'll deploy a crul query that transforms REST API responses from Monday.com into vector embeddings that are then loaded into a Pinecone vector database on a set schedule
Use case
We want to get board items from Monday.com, transform them into vector embeddings, then load into a Pinecone vector database. We'll also demonstrate how to semantically query the embeddings from crul!
If you're not familiar with Monday.com, think of it as an all-in-one work management platform that helps teams streamline their workflow, collaborate seamlessly, and manage complex projects effectively.
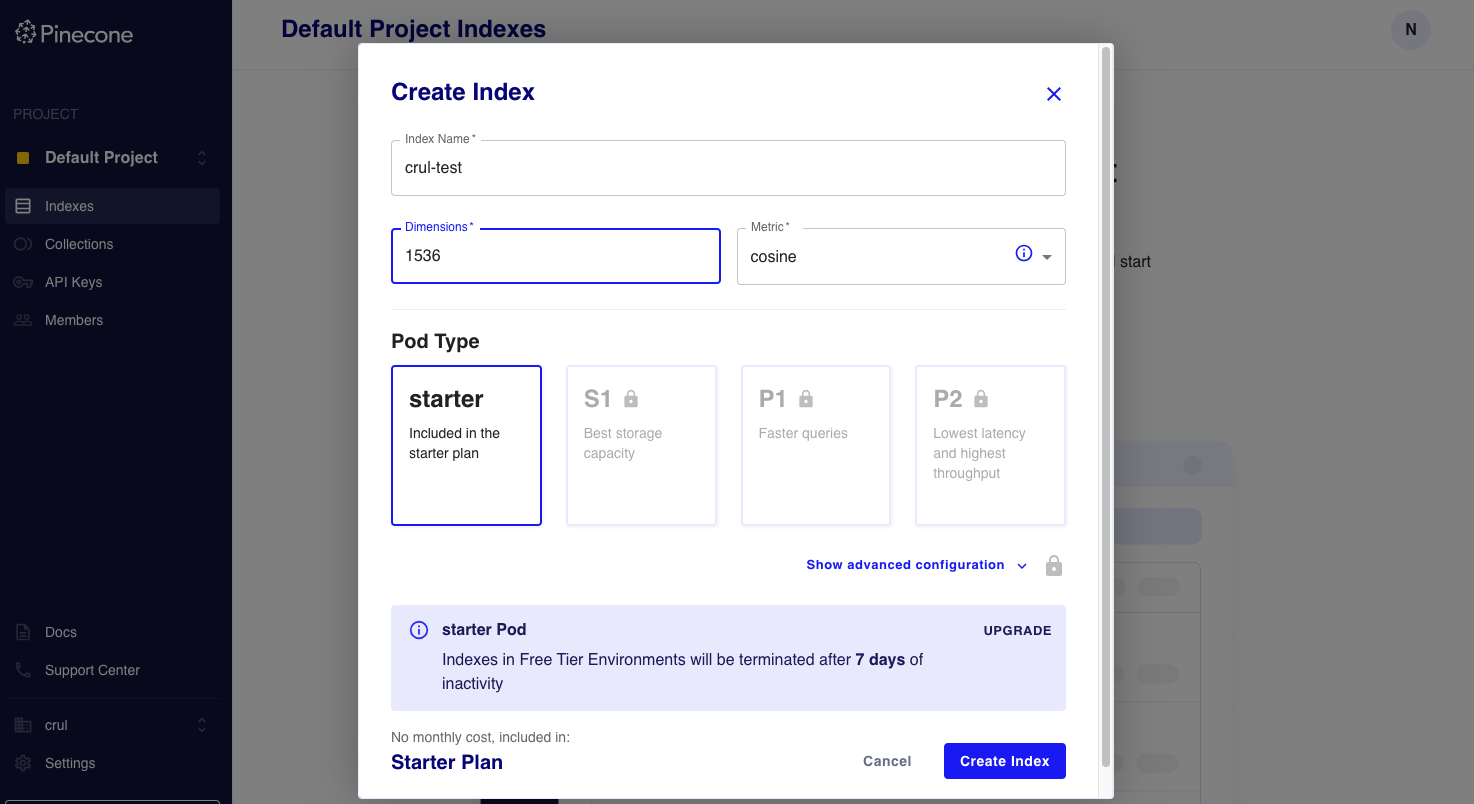
Prerequisites
We will need a global API token for the Monday.com API. This API token will need to be configured as a custom credential.
We will also need an API key for the Pinecone REST API. This API key will also need to be configured as a Pinecone credential.
Finally we'll need a Pinecone index that is configured with the same dimensions as the vector embeddings generated by the vectorize command (1536). Keep track of the name of the index as you will need it for future stages.
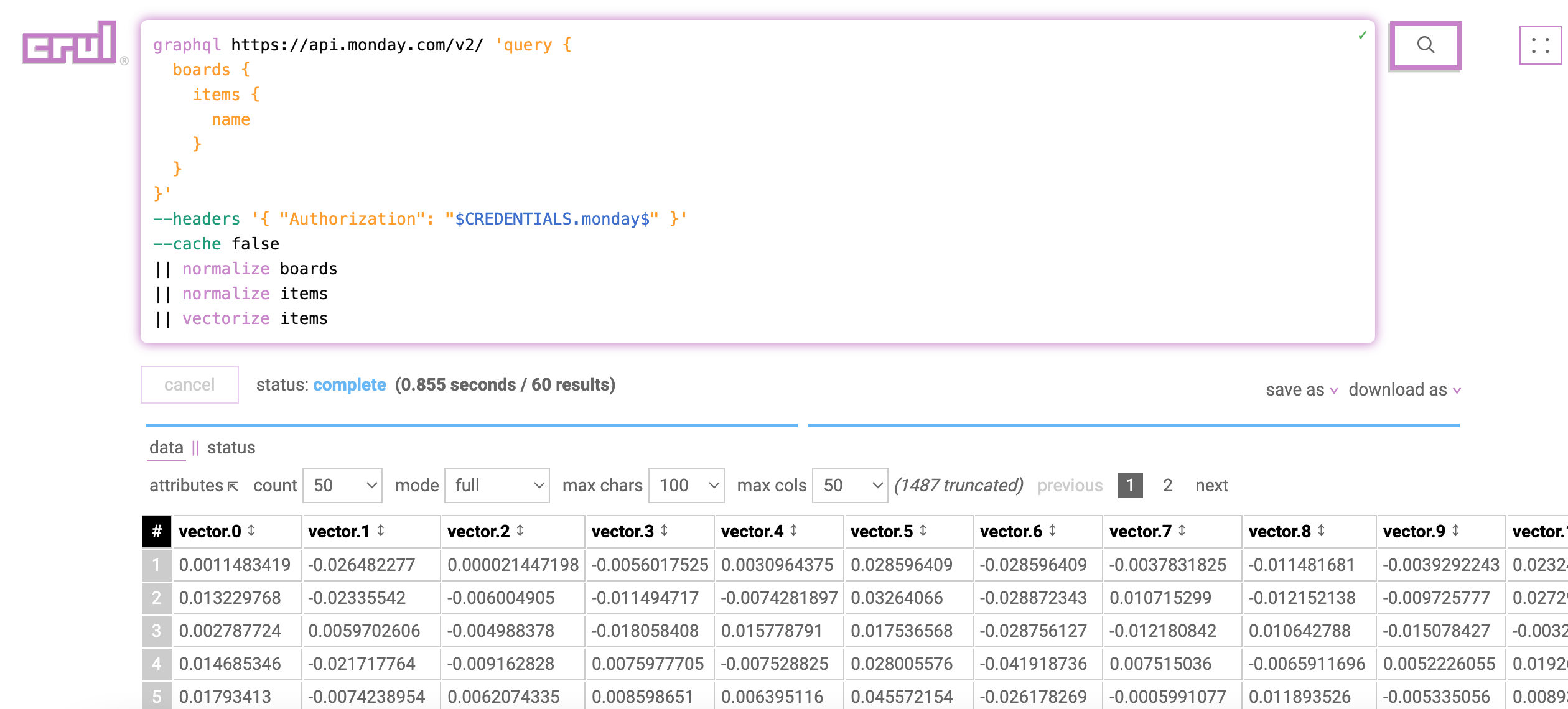
The query
Here is the entire query, we'll walk through it step by step next.
graphql https://api.monday.com/v2/ 'query {
boards {
items {
name
}
}
}'
--headers '{ "Authorization": "$CREDENTIALS.monday$" }'
|| normalize boards
|| normalize items
|| diff vectorized_board_items --update true
|| vectorize item
|| vectorload --pinecone.index "{INDEX}.pinecone.io"
Building our query
Retrieving board items
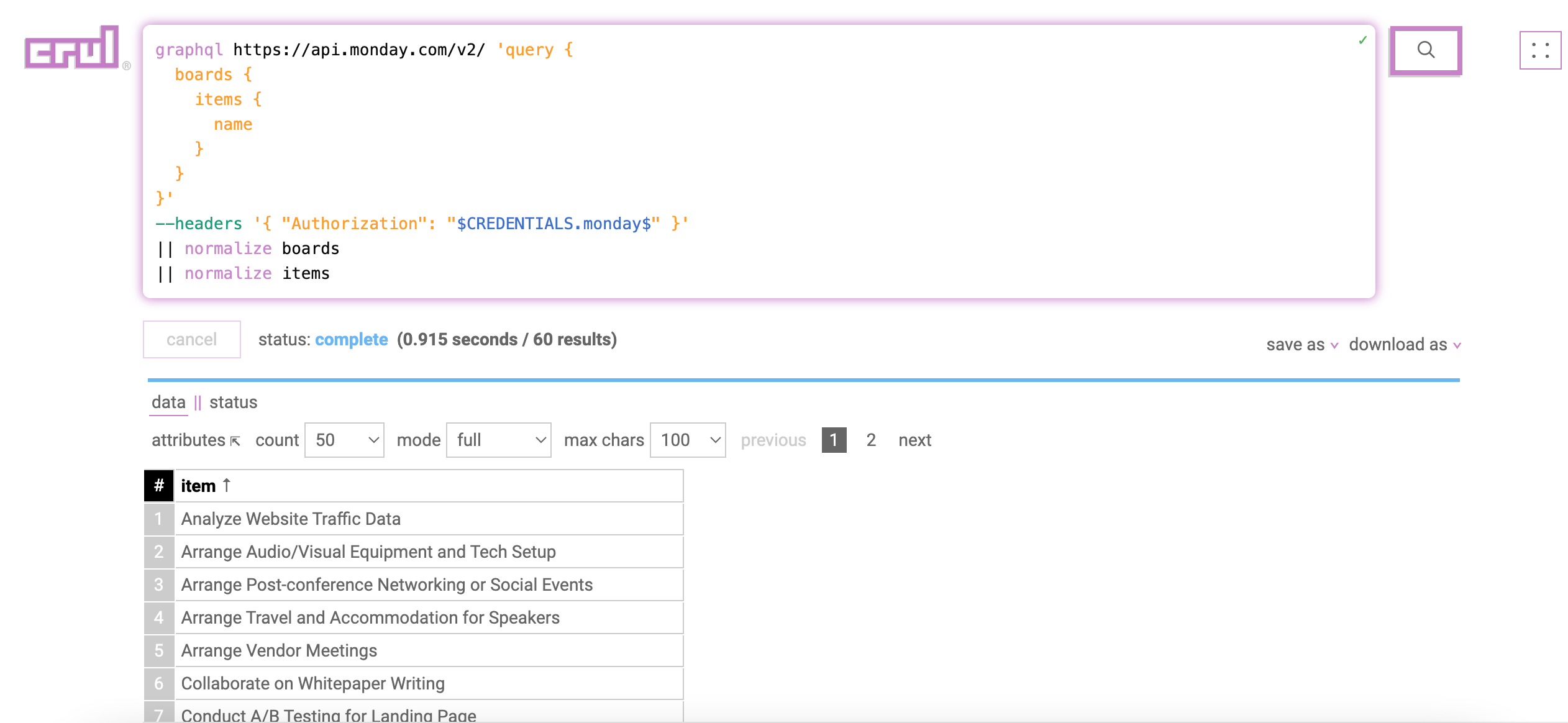
We first need to retrieve board items from our Monday.com account. The Monday.com API uses GraphQL to access resources, so we'll use the graphql command to list all current board items.
The normalize commands will convert the GraphQL response into a tabular format.
graphql https://api.monday.com/v2/ 'query {
boards {
items {
name
}
}
}'
--headers '{ "Authorization": "$CREDENTIALS.monday$" }'
|| normalize boards
|| normalize items
Converting board items to vector embeddings
The vectorize command can be used to easily turn the values in a particular column into vector embeddings using OpenAI. This stage will convert the item column to vector embeddings
...
|| vectorize items
You can override the deafult model, or construct a query to another vector embedding generating API using the api/curl commands.
Loading vector embeddings
The vectorload command will simply load all rows (which should contain vector embeddings) into a pinecone index.
...
|| vectorload --pinecone.index "{INDEX}.pinecone.io"
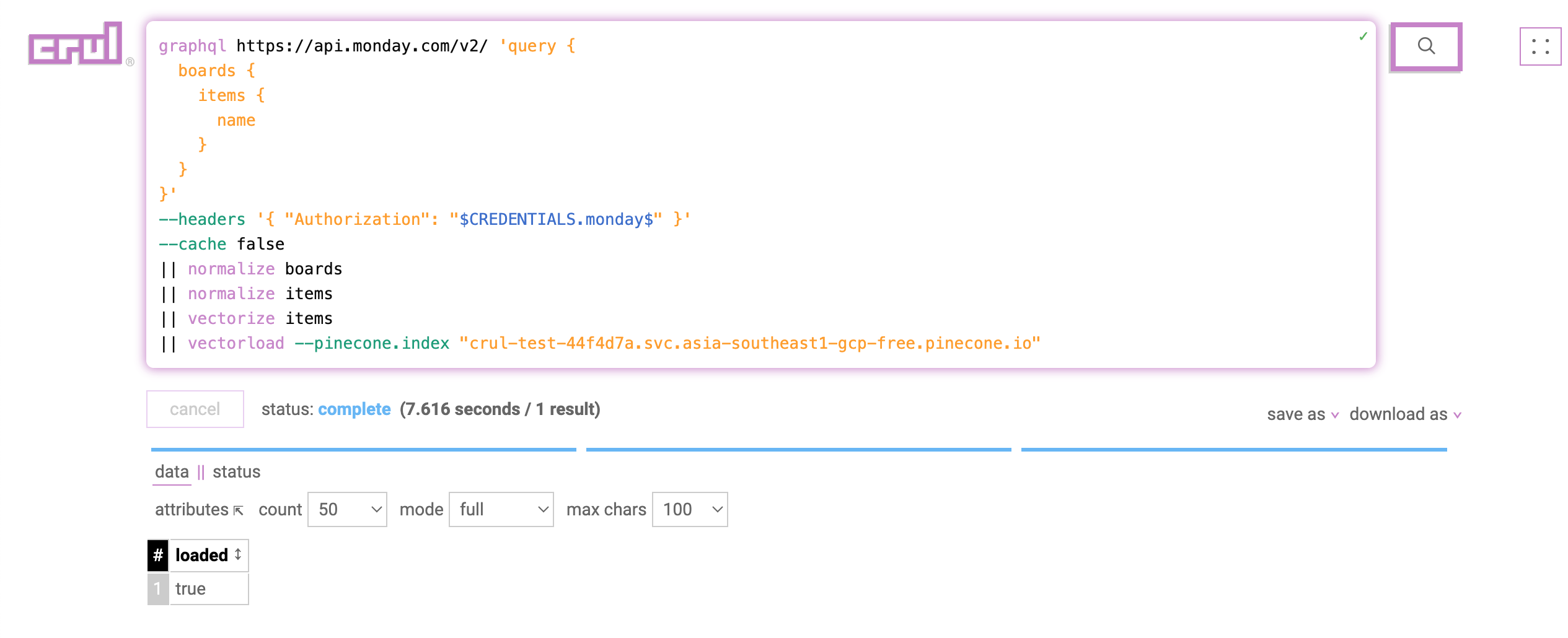
Test by querying our vector database
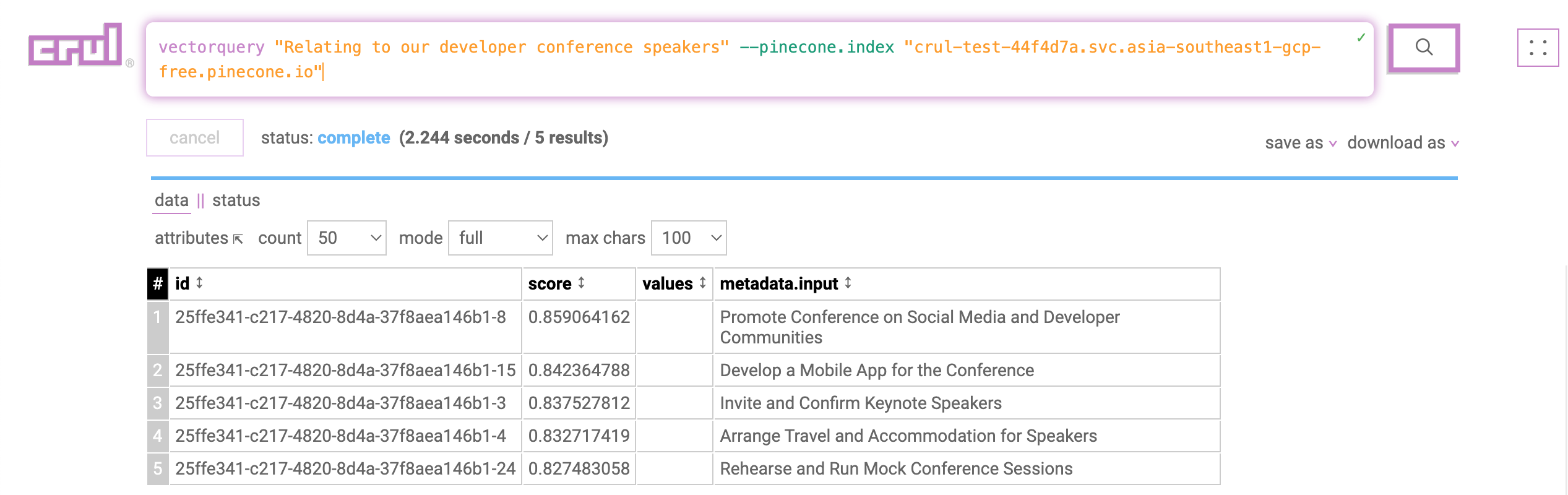
We can test if our embeddings were loaded correctly by directly querying the vector database from crul with a semantic query using the vectorquery command. You will want to run this query in a new tab as it does not depend on the previous stages.
vectorquery "Tasks relating to our upcoming user conference" --pinecone.index "{INDEX}.pinecone.io"
Optional diffing
We may want to incorporate a diff to prevent sending the same embeddings multiple times. We can do this using the diff command, which will maintain a set of board items that have already been converted to vector embeddings and loaded into a pinecone index.
The diff command can be configured to run with a number of different strategies to maintain, update, etc. the diff. See the diff command for more details.
We'll want to run it prior to the vectorize command, so that we only vectorize new items.
...
|| diff vectorized_board_items --update true
Advanced
We could also use checkpoints combined with dates to retrieve new and/or edited items based off of the current timestamp $TIMESTAMP$ or $TIMESTAMP.ISO$. Once we have made the request, we can save the checkpoint, and access and reuse it next time the query runs.
This has a similar result to diff, and could be used in combination. It is an important consideration if the number of boards/items is expected to continue to increase.
Scheduling
The last step is to schedule our query to run on a set interval. First let's copy the query. Then, from the menu, navigate to the scheduler admin page.
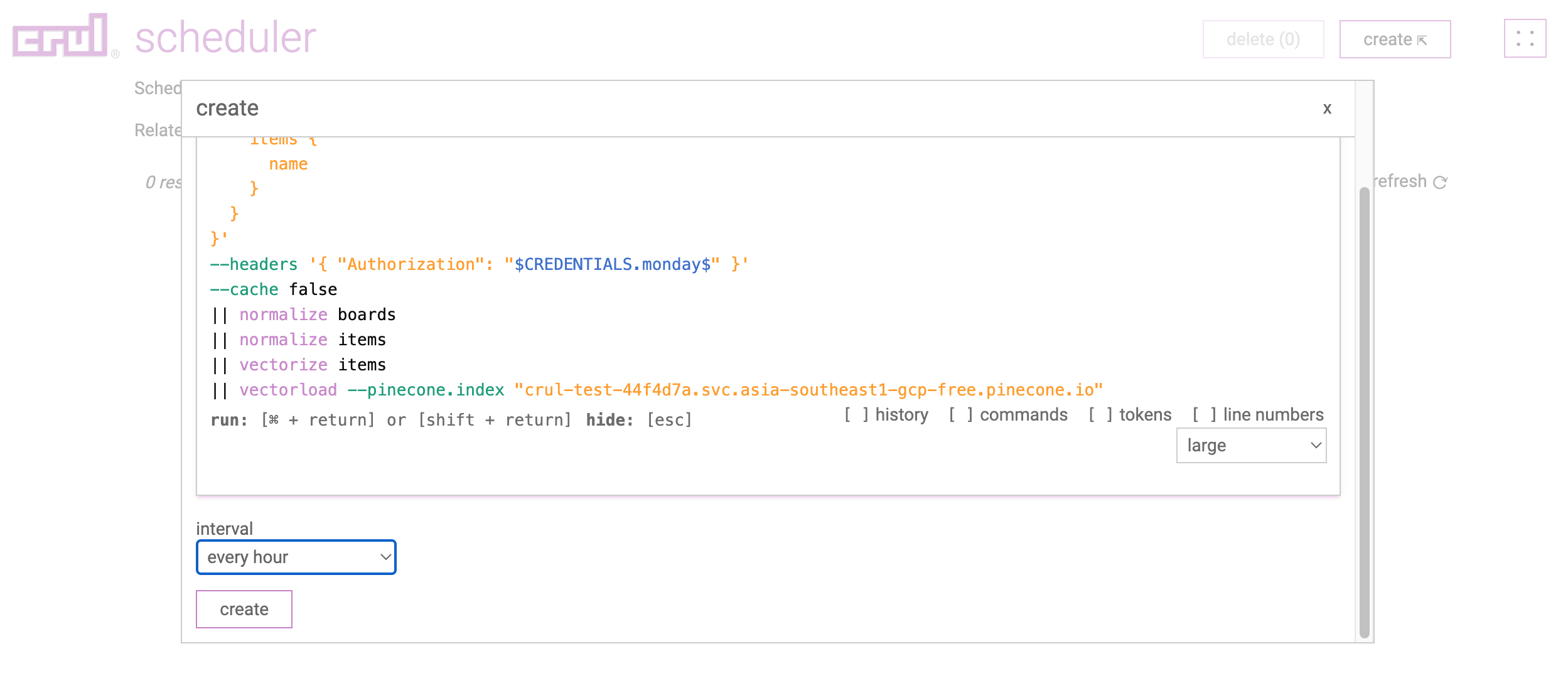
Provide a name, the query, add the desired interval, and submit.
Now our query will run on the set interval and populate our vector database index!
Summary
We've now seen how simple it is to create a query that transforms GraphQL API responses into vector embeddings and loads them into a Pinecone vector database. We can also query that database all from within crul!
It's not just Pinecone! Send to one of 30+ stores using the freeze command, or construct your own api/curl command to make generic REST requests to another destination or vector database.
Any crul query can be turned into a feed of vector embeddings using these steps! Have a web page that you would like turned into vector embeddings? No problem! Need to turn a REST API into a data feed? We got you!
Join our community
Come hang out and ask us any questions. Many of the features and fixes in crul come from our user requests!